

DAM-3B(Describe Anything 3B)是英伟达推出的多模态大语言模型,专为生成图像和视频中特定区域的详细描述设计。模型通过点、边界框、涂鸦或掩码等方式指定目标区域,能生成精准且符合上下文的描述文本。 DAM-3B的核心创新包括“焦点提示”技术和“局部视觉骨干网络”。焦点提示技术将全图信息与目标区域的高分辨率裁剪图融合,确保细节不失真,同时保留整体背景。局部视觉骨干网络则通过嵌入图像和掩码输入,运用门控交叉注意力机制,将全局特征与局部特征相结合,再传输至大语言模型生成描述。

(图片来源网络,侵删)

(图片来源网络,侵删)









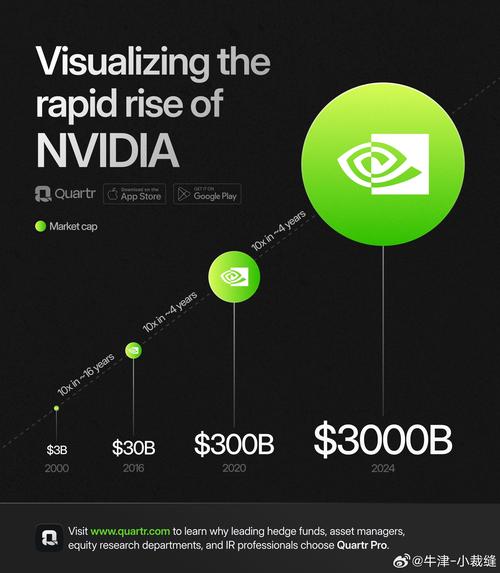
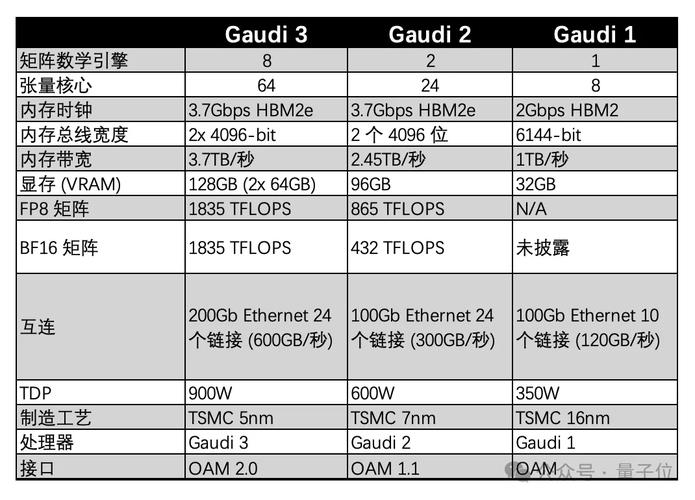


全部评论
留言在赶来的路上...
发表评论