ConsisID是北京大学和鹏城实验室等机构推出的文本到视频(Text-to-Video, IPT2V)生成模型,基于频率分解技术保持视频中人物身份的一致性。模型用免调优(tuning-free)的Diffusion Transformer(DiT)架构,结合低频全局特征和高频内在特征,用分层训练策略生成高质量、可编辑且身份一致性强的视频。ConsisID在多个评估维度上超越现有技术,推动了身份一致性视频生成技术的发展。

(图片来源网络,侵删)

(图片来源网络,侵删)


ConsisID是北京大学和鹏城实验室等机构推出的文本到视频(Text-to-Video, IPT2V)生成模型,基于频率分解技术保持视频中人物身份的一致性。模型用免调优(tuning-free)的Diffusion Transformer(DiT)架构,结合低频全局特征和高频内在特征,用分层训练策略生成高质量、可编辑且身份一致性强的视频。ConsisID在多个评估维度上超越现有技术,推动了身份一致性视频生成技术的发展。

HoloTime 是北京大学深圳研究生院和鹏城实验室推出的全景 4D 场景生成框架,基于视频扩散模型将单张全景图像转化为具有真实动态效果的全景视频,进一步重建为沉浸式的 4D 场景。...


Dive3D是北京大学和小红书公司合作推出的文本到3D生成框架。框架基于分数的匹配(Score Implicit Matching,SIM)损失替代传统的KL散度目标,有效避免模式坍塌问题,显著提升3D生成内容的多样性。...

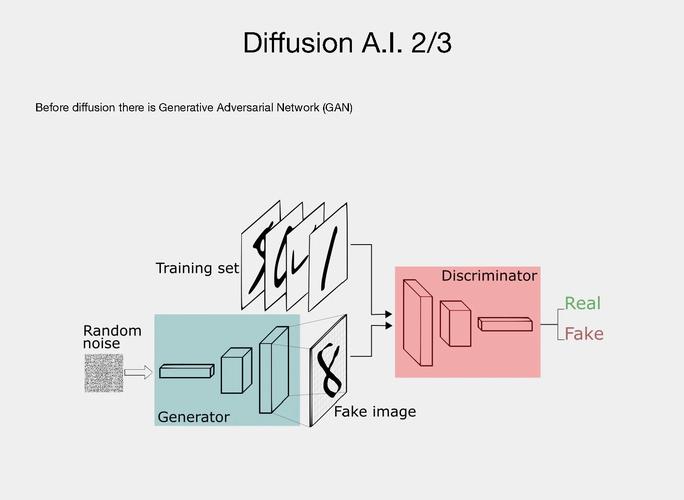
DiffSplat是新型的 3D 生成方法,从文本提示和单视图图像快速生成 3D 高斯点阵(Gaussian Splats)。通过微调预训练的文本到图像扩散模型,基于强大的 2D 先验知识,引入 3D 渲染损失来确保生成的...
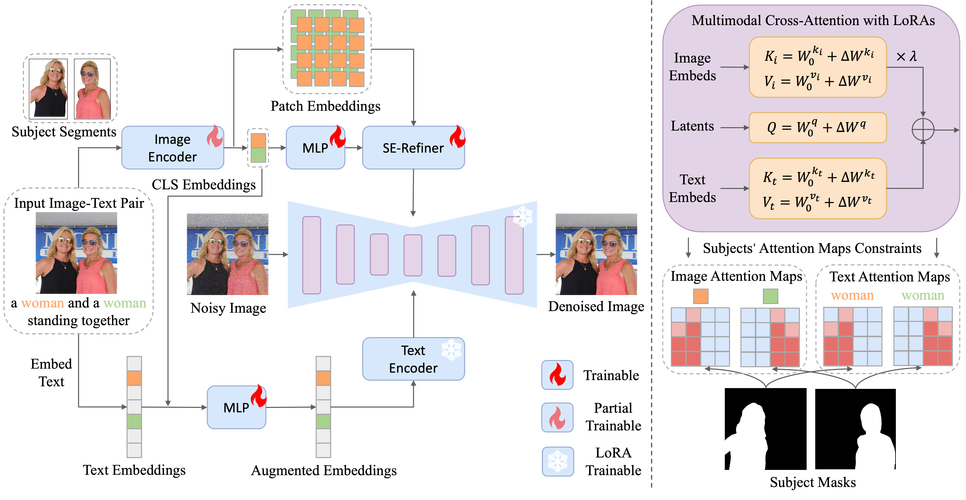
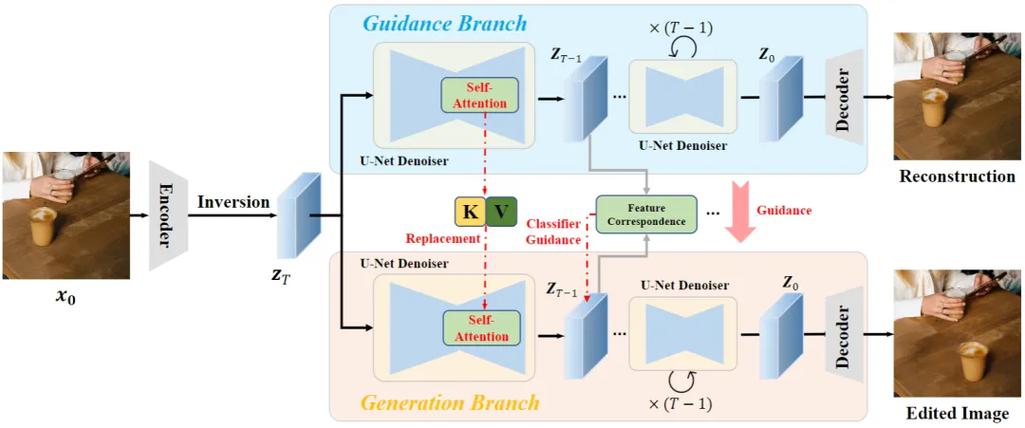
DiffEditor是北京大学深圳研究生院与腾讯PCG的研究团队提出的基于扩散模型(Diffusion Model)的图像编辑工具,通过引入图像提示(image prompts)和文本提示,结合区域随机微分方程(Region...
全部评论
留言在赶来的路上...
发表评论