

CodeElo 是用于评估大型语言模型(LLMs)在编程竞赛级别能力的基准测试工具。通过与人类程序员的 Elo 评级系统进行比较,来衡量 LLMs 的编程水平。工具从 CodeForces 平台选择题目,按比赛分区、难度级别和算法标签进行分类,确保问题的多样性和代表性。CodeElo 的评估方法非常稳健,提交的代码直接在 CodeForces 平台上进行测试,基于特殊的评估机制,确保准确判断代码的正确性。使用 Elo 评级系统来计算评分,考虑问题难度并对错误进行惩罚。在对多个开源和专有 LLM 进行测试后,OpenAI 的 o1-mini 模型表现最佳,超过了 90% 的人类参与者。CodeElo 的推出旨在解决现有基准测试的局限性,提供一个更全面、准确的评估环境,帮助研究人员和开发者更好地理解和改进 LLMs 的能力。

(图片来源网络,侵删)

(图片来源网络,侵删)





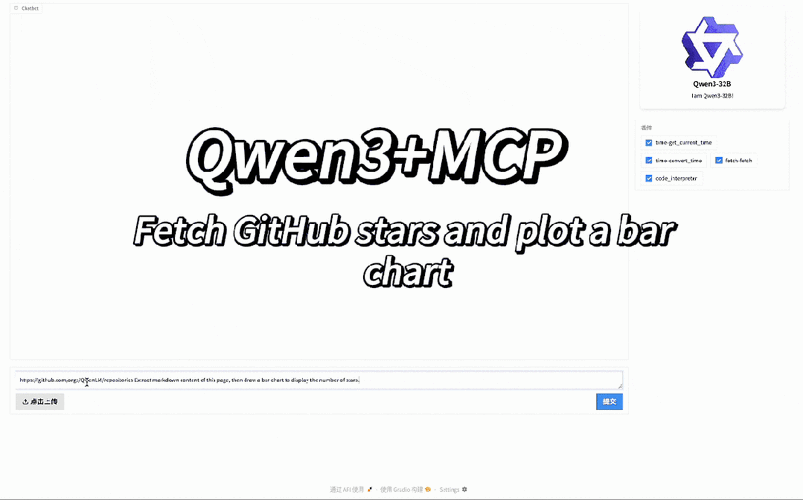
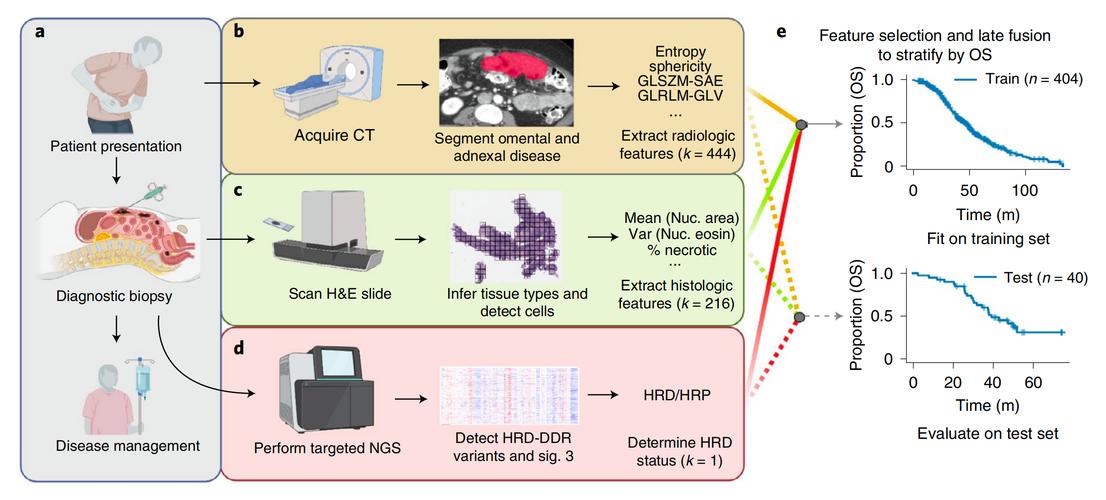
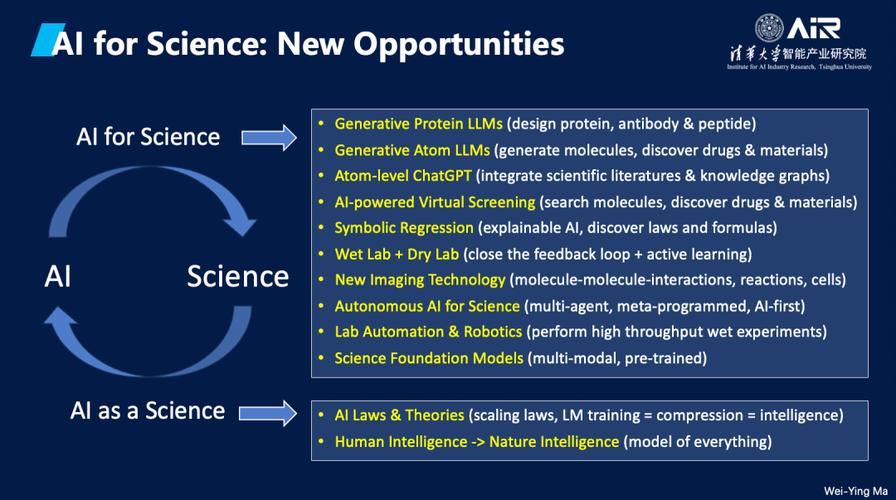


全部评论
留言在赶来的路上...
发表评论