AxBench 是斯坦福大学推出的评估语言模型(LM)可解释性方法的基准测试框架。基于合成数据生成训练和评估数据,比较不同模型控制技术在概念检测和模型转向两个方面的表现。概念检测任务基于标记的合成数据评估模型对特定概念的识别能力;模型转向任务用长文本生成任务评估模型在干预后的表现,用另一个语言模型作为“裁判”评分。AxBench为研究者提供统一的平台,用在系统地评估和比较各种语言模型控制方法的有效性,推动语言模型的安全性和可靠性研究。

(图片来源网络,侵删)

(图片来源网络,侵删)


AxBench 是斯坦福大学推出的评估语言模型(LM)可解释性方法的基准测试框架。基于合成数据生成训练和评估数据,比较不同模型控制技术在概念检测和模型转向两个方面的表现。概念检测任务基于标记的合成数据评估模型对特定概念的识别能力;模型转向任务用长文本生成任务评估模型在干预后的表现,用另一个语言模型作为“裁判”评分。AxBench为研究者提供统一的平台,用在系统地评估和比较各种语言模型控制方法的有效性,推动语言模型的安全性和可靠性研究。

WorldScore 是斯坦福大学提出的用于世界生成模型的统一评估基准。将世界生成分解为一系列的下一个场景生成任务,通过明确的基于相机轨迹的布局规范来实现不同方法的统一评估。...


VideoAgent是一种自改进的视频生成系统,由斯坦福大学、滑铁卢大学、DeepMind等机构的研究人员共同推出。根据图像观察和语言指令生成视频计划,转换为机器人控制动作。VideoAgent基于自我条件一致性方法细化视频...

ToddlerBot是斯坦福大学开源的用在运动操作的开源机器学习与人形机器人平台,为高效收集大规模、高质量的训练数据设计。ToddlerBot具备30个主动自由度,用Dynamixel电机,总成本控制在6000美元以内。基于...


SleepFM 是斯坦福大学开源的多模态睡眠分析模型,基于超过14,000名参与者的100,000小时睡眠数据,通过融合大脑活动、心电图和呼吸信号,提供全面的睡眠健康评估。旨在提高睡眠分析的效率和准确性。...
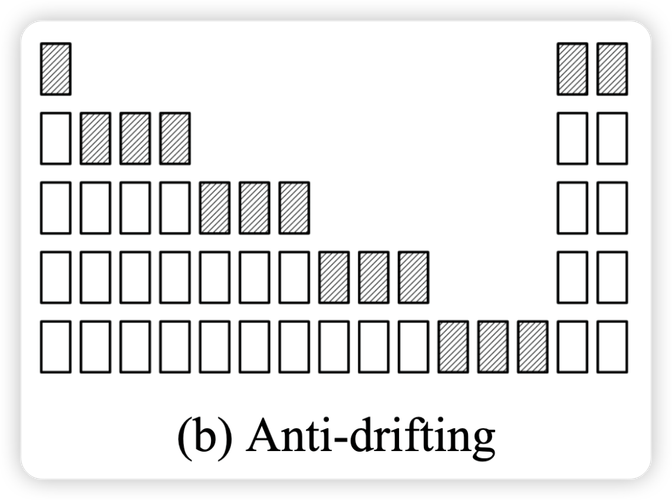
FramePack 是斯坦福大学开源的AI视频生成模型。基于压缩输入帧的上下文长度,解决视频生成中的“遗忘”和“漂移”问题,让模型能高效处理大量帧,保持较低的计算复杂度。FramePack 仅需 6GB 显存在普通笔记本电脑...
全部评论
留言在赶来的路上...
发表评论