


在实际应用中,通常优先使用小批量,以获得更好的泛化能力和计算效率。
我们设置的批次大小是一个超参数,需要根据模型架构和数据集大小进行实验。确定最佳批次大小的有效方法是实施交叉验证策略。
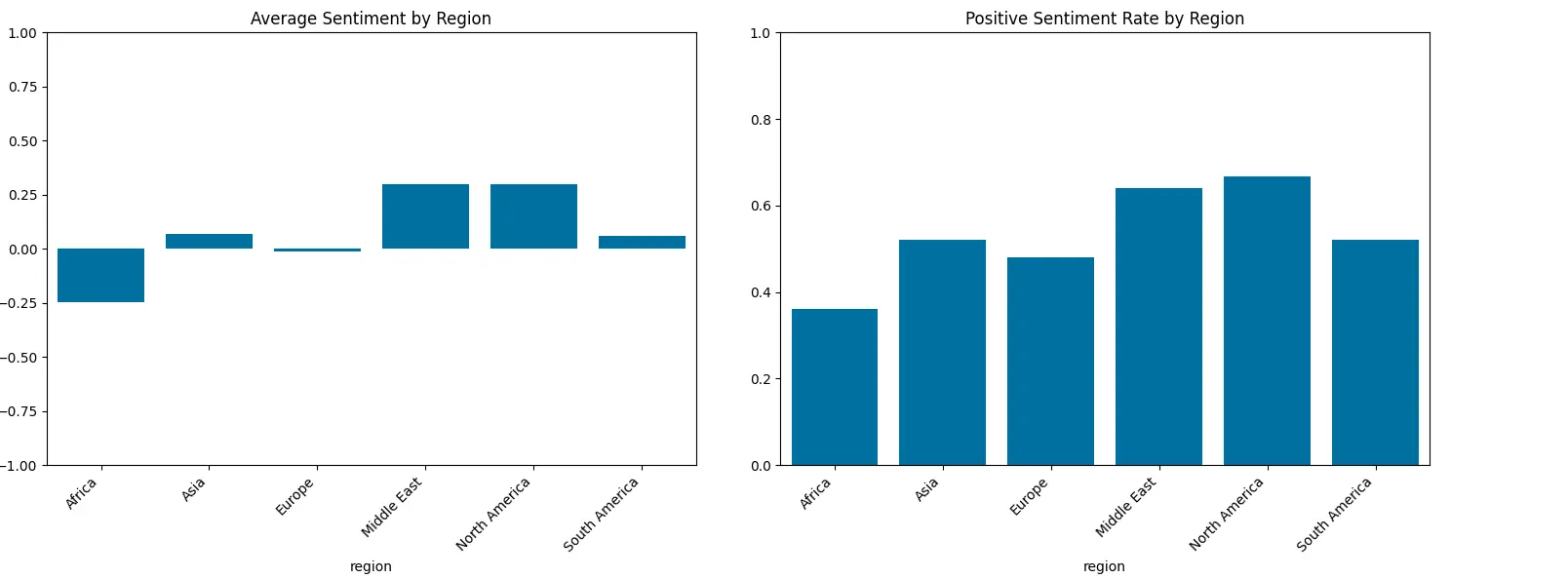
下表可以帮助您做出此决定:
注意:如上所述,batch_size 是一个超参数,需要根据模型训练进行微调。因此,有必要了解较低和较高批次大小值的性能。
较小的批次大小值通常介于 1 到 64 之间。由于梯度更新频率更高(每批次),模型可以更早地开始学习,并快速更新权重,因此更新速度更快。恒定的权重更新意味着一个周期需要更多次迭代,这会增加计算开销,从而延长训练时间。
梯度估计中的“噪声”有助于避免尖锐的局部最小值和过拟合,通常可以提高测试性能,从而展现出更好的泛化能力。此外,由于这些噪声的存在,收敛可能会不稳定。如果学习率很高,这些噪声梯度可能会导致模型超调并发散。
将小批次大小想象成朝着目标迈出频繁但不稳定的步伐。你可能不会走直线,但你可能会发现一条总体上更好的路径。
可以考虑使用 128 及以上的大批量。较大的批量可以实现更稳定的收敛,因为每个批量包含的样本越多,平均梯度就越平滑,越接近损失函数的真实梯度。如果梯度平滑,模型可能无法摆脱平坦或尖锐的局部最小值。
这样,完成一个迭代周期所需的迭代次数就越少,从而可以加快训练速度。大批量需要更多内存,这需要 GPU 来处理这些巨大的数据块。虽然每个迭代周期的速度更快,但由于更新步长较小且梯度噪声较少,可能需要更多迭代周期才能收敛。
大批量就像按照预先规划好的步数稳步朝着目标前进,但有时你可能会因为没有探索所有其他路径而陷入困境。
这里有一个比较全批量和小批量训练的综合表格。
在批量训练和小批量训练之间进行选择时,请考虑以下几点:
批处理和小批量训练是深度学习模型优化中必须掌握的基础概念。虽然全批量训练能够提供最稳定的梯度,但正如本文开头所述,由于内存和计算能力的限制,它很少适用于现代大规模数据集。另一方面,小批量训练则实现了恰到好处的平衡,借助 GPU/TPU 加速,提供了良好的速度、泛化能力和兼容性。因此,它已成为大多数实际深度学习应用的事实上的标准。
选择最佳批量大小并非一刀切的决策。它应该以数据集的大小以及现有的内存和硬件资源为指导。此外,还需要考虑优化器的选择以及所需的泛化能力和收敛速度,例如 learning_rate 和 decay_rate。通过理解这些动态因素,并利用学习速率调度、自适应优化器(如 ADAM)和批量大小调整等工具,我们可以更快、更准确、更高效地创建模型。





全部评论
留言在赶来的路上...
发表评论