AI工具
发布文章-
发布了文章 2个月前
Mu – 微软推出的小参数语言模型
Mu是微软推出的小参数语言模型,仅3.3亿参数,支持在 NPU 和边缘设备上高效运行。模型基于编码器解码器架构,基于硬件感知优化、模型量化及特定任务微调,实现每秒超100 tokens的响应速度。...
-
发布了文章 2个月前
MoviiGen 1.1 – AI视频生成模型,支持生成电影级画质
MoviiGen 1.1 是ZulutionAI推出的专注于生成电影级画质视频的AI模型。模型基于 Wan2.1 微调而成,经过专业电影制作人和AIGC创作者在60个美学维度上的评估,表现出色。...
-
发布了文章 2个月前
MovieDreamer – 专为长视频研发的AI视频生成框架
MovieDreamer是浙江大学联合阿里巴巴专为长视频研发的AI视频生成框架。结合自回归模型和扩散渲染技术,能生成具有复杂情节和高视觉质量的长视频。...
-
发布了文章 2个月前
Movie Gen – Meta推出文本驱动的AI视频生成与编辑工具
Movie Gen 是 Meta 推出的AI视频生成工具,能根据文本提示生成和编辑视频,为视频配上同步音频。技术包括创建长达16秒的高清视频、为现有视频配上音频、编辑视频以及基于照片制作定制视频。...
-
发布了文章 2个月前
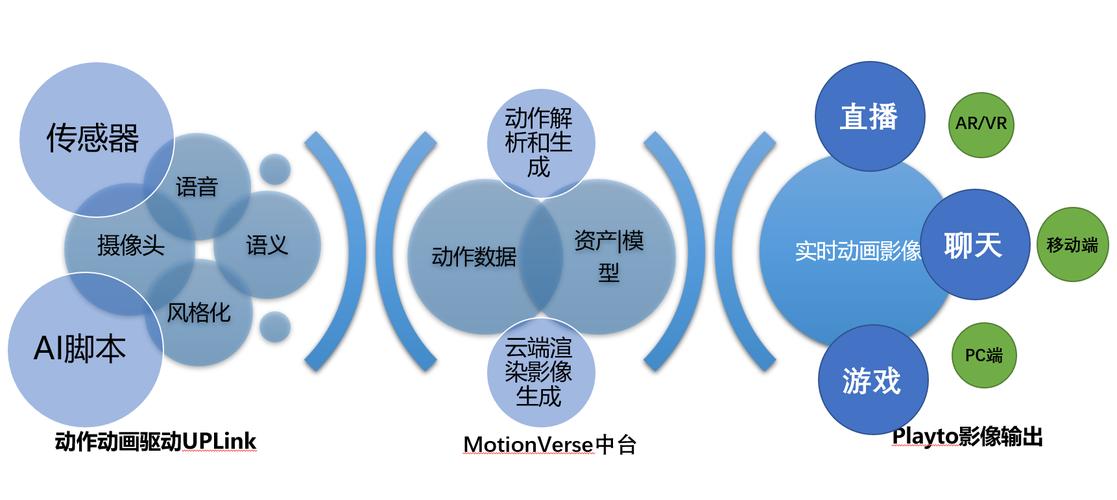
MotionGen – 元象科技推出的3D动作生成模型
MotionGen是元象科技推出的3D动作生成模型,结合了大模型、物理仿真和强化学习算法,支持用户仅通过简单文本指令即可快速生成逼真且流畅的3D动作。MotionGen极大地简化了3D动画的制作过程,提高了创作效率。Moti...
-
发布了文章 2个月前
MotionCtrl – 腾讯等推出的视频生成模型的运动控制器
MotionCtrl是由来自腾讯和香港大学等机构的研究人员推出的一个为视频生成模型设计的统一且灵活的运动控制器,能够独立地控制视频中的相机运动和物体运动视角。该系统由两个主要模块组成:相机运动控制模块和物体运动控制模块,可以...
-
发布了文章 2个月前
MotionClone – 文本驱动的AI视频动作克隆框架
MotionClone是文本驱动的AI视频动作克隆框架,通过时间注意力机制从参考视频中克隆动作,结合文本提示词生成新视频。能处理复杂的全局相机运动和精细的局部肢体动作,实现高度逼真和控制性强的视频内容创作。...
-
发布了文章 2个月前
MotionCanvas – 港中文和 Adobe 等机构推出的可控图像到视频生成方法
MotionCanvas是香港中文大学、Adobe 研究院和莫纳什大学推出的图像到视频(I2V)生成方法,能将静态图像转化为具有丰富动态效果的视频。MotionCanvas基于引入运动设计模块,让用户能直观地在图像上规划相机...
-
发布了文章 2个月前
MotionCLR – AI动作编辑模型,根据文本提示生成相应的动作序列
MotionCLR是基于注意力机制的人体动作生成和编辑模型,能根据文本提示生成动作,支持用户进行交互式编辑,如动作强调、减弱、替换、擦除和风格转移。MotionCLR基于自注意力和交叉注意力机制理解和编辑动作,支持多样化的动...
-
发布了文章 2个月前
Motion Prompting – 谷歌联合密歇根和布朗大学推出的运动轨迹控制视频生成模型
Motion Prompting是 Google DeepMind、密歇根大学和布朗大学联合推出的视频生成技术,基于运动轨迹(motion trajectories)控制和引导视频内容的生成。Motion Prompting...
-
发布了文章 2个月前
Motion Dreamer – 香港科技大学推出的运动合理视频生成框架
Motion Dreamer是香港科技大学(广州)研究者提出的视频生成框架,生成运动合理视频。基于两阶段生成方式,先基于输入图像和运动条件生成中间运动表示,再利用该表示生成高细节视频。其引入实例流这一新运动模态,可实现从稀疏...
-
发布了文章 2个月前
Motion Anything – 腾讯联合京东等高校推出的多模态运动生成框架
Motion Anything 是澳大利亚国立大学、悉尼大学、腾讯、麦吉尔大学、京东等机构推出的多模态运动生成框架,根据文本、音乐或两者的组合生成高质量、可控的人类运动。Motion Anything引入基于注意力的掩码建模...
-
发布了文章 2个月前
Motia – AI Agent 开发框架,支持多种编程语言、一键部署智能体
Motia 是专为软件工程师设计的 AI Agent 框架,简化 AI 智能体的开发、测试和部署过程。支持多种编程语言,如 Python、TypeScript 和 Ruby,开发者可以使用熟悉的语言编写智能体逻辑,无需学习专...
-
发布了文章 2个月前
MoshiVis – Kyutai 开源的多模态实时语音模型
MoshiVis 是 Kyutai 推出的开源多模态语音模型,基于 Moshi 实时对话语音模型开发,增加了视觉输入功能。能实现图像的自然、实时语音交互,将语音和视觉信息相结合,让用户可以通过语音与模型交流图像内容。...
-
发布了文章 2个月前
Moshi – 法国AI实验室Kyutai开发的实时音频多模态模型
Moshi是由法国的的人工智能研究实验室Kyutai推出的一款端到端实时音频多模态AI模型,拥有听、说、看的能力,并能模拟70种不同的情绪和风格进行交流。作为对标GPT-4o的开源模型,Moshi在普通笔记本上即可运行,具有...