tolua 优化
-
发布了文章 2个月前
TPO – AI优化框架,动态调整推理模型的输出,更符合人类偏好
TPO(Test-Time Preference Optimization)是新型的AI优化框架,在推理阶段对语言模型输出进行动态优化,更符合人类偏好。TPO通过将奖励信号转化为文本反馈,将模型生成的优质响应标记为“选择”输...
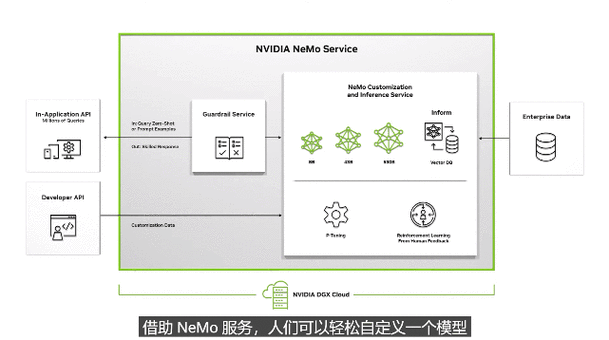
没有更多内容



TPO(Test-Time Preference Optimization)是新型的AI优化框架,在推理阶段对语言模型输出进行动态优化,更符合人类偏好。TPO通过将奖励信号转化为文本反馈,将模型生成的优质响应标记为“选择”输...
没有更多内容