训练模型原理
-
发布了文章 2个月前
RAGEN – 训练大模型推理 Agent 的开源强化学习框架
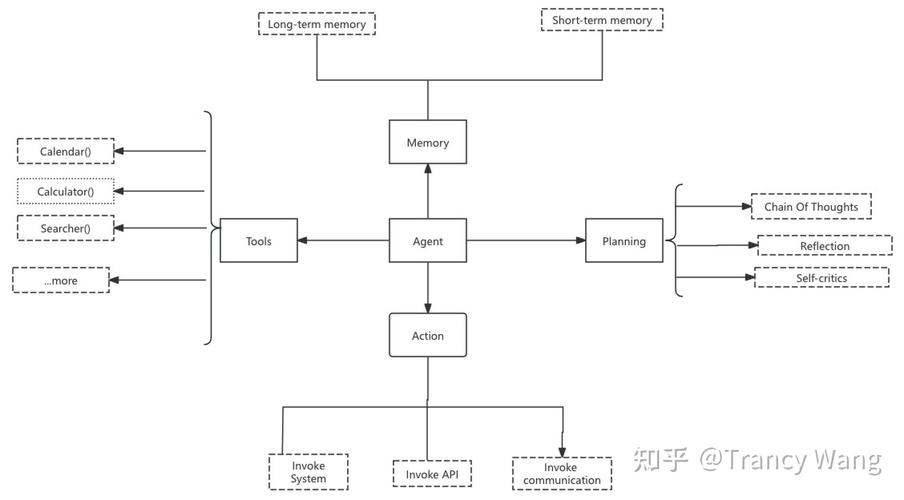
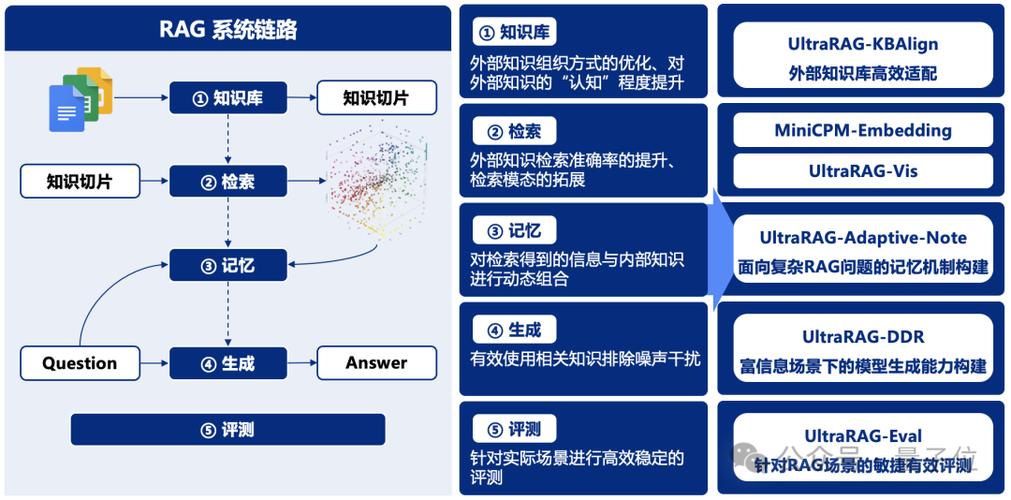
RAGEN是开源的强化学习框架,用于在交互式、随机环境中训练大型语言模型(LLM)推理Agent。基于StarPO(State-Thinking-Action-Reward Policy Optimization)框架,通过...
没有更多内容



RAGEN是开源的强化学习框架,用于在交互式、随机环境中训练大型语言模型(LLM)推理Agent。基于StarPO(State-Thinking-Action-Reward Policy Optimization)框架,通过...
没有更多内容