

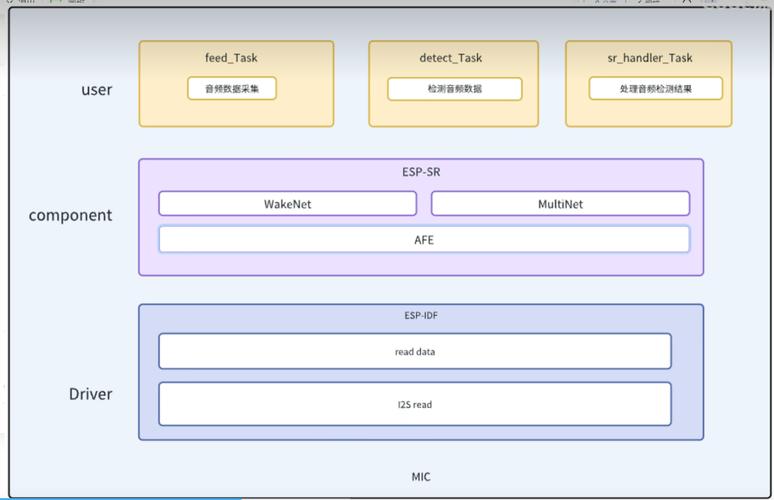
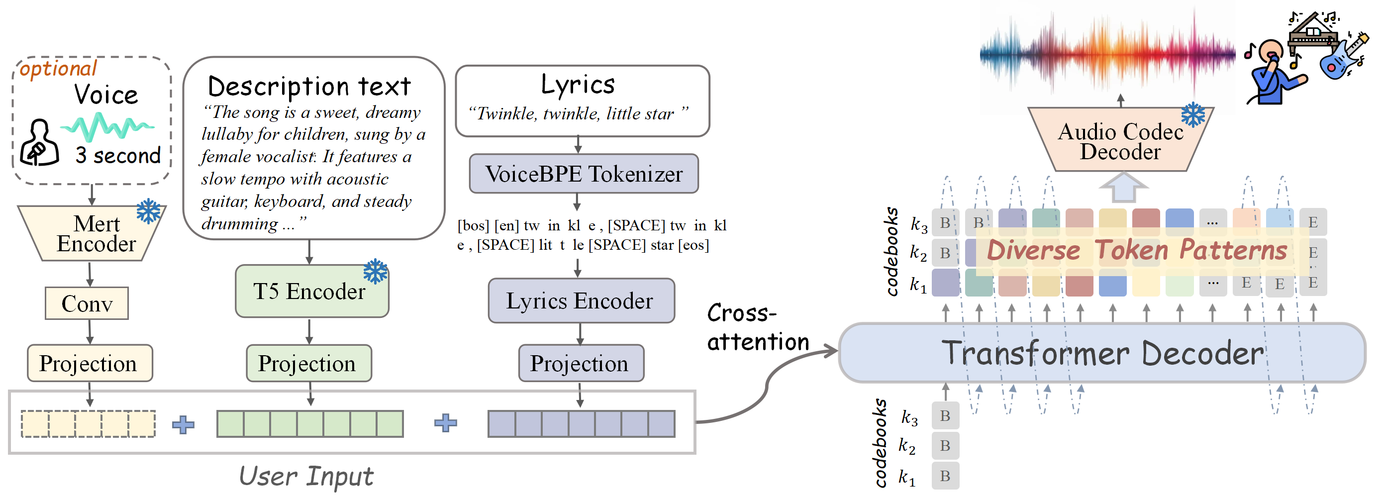
语音开源框架
-
发布了文章 2个月前
Voila – 开源端到端语音大模型,实现低延迟语音对话
Voila 是开源的端到端语音大模型,专为语音交互而设计。具备高保真、低延迟的实时流式音频处理能力,能直接处理语音输入并生成语音输出,为用户提供流畅且自然的交互体验。...
-
发布了文章 2个月前
VoiceCraft – 开源的语音编辑和文本转语音模型
VoiceCraft是一个由德克萨斯大学奥斯汀分校研究团队开源的神经编解码器语言模型,专注于零样本语音编辑和文本到语音(TTS)任务。该模型采用Transformer架构,通过创新的token重排过程,结合因果掩蔽和延迟叠加...
-
发布了文章 2个月前
OuteTTS – 开源的文本到语音合成项目,基于纯语言建模方法生成语音
OuteTTS是开源的文本到语音(TTS)项目,基于纯语言建模的方法生成语音。OuteTTS项目基于LLaMa架构,用Oute3-350M-DEV基础模型,拥有3.5亿参数。OuteTTS具备音频标记化、CTC强制对齐技术和...
-
发布了文章 2个月前
Oliva – 开源语音RAG助手,实时语音搜索向量数据库
Oliva 是开源的语音RAG助手,结合 Langchain 和 Superlinked 技术,基于语音驱动的 RAG(检索增强生成)架构,帮助用户在 Qdrant 向量数据库中实时搜索信息。用户基于自然语音提问,Oliva...
-
发布了文章 2个月前
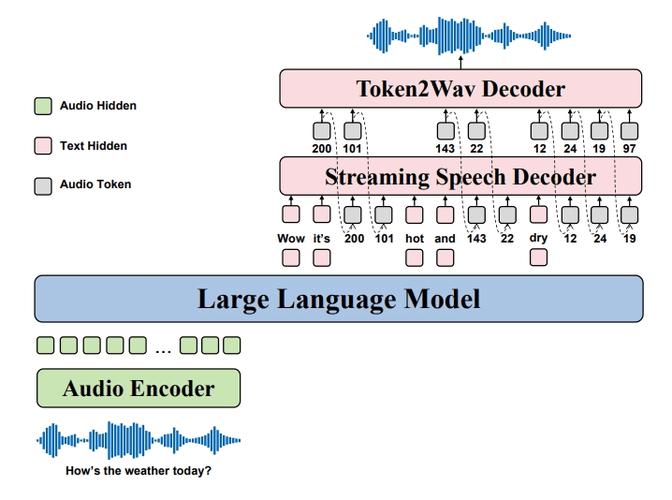
Ichigo – 开源的多模态AI语音助手,实时处理语音和文本的交织序列
Ichigo是开源的多模态AI语音助手,采用混合模态模型,能实时处理语音和文本的交织序列。基于将语音直接量化为离散令牌,用统一的变换器架构同时处理语音和文本,实现跨模态的联合推理和生成。...



没有更多内容