

the information 字节跳动
-
发布了文章 2个月前
XVerse – 字节跳动推出的多主体控制图像生成模型
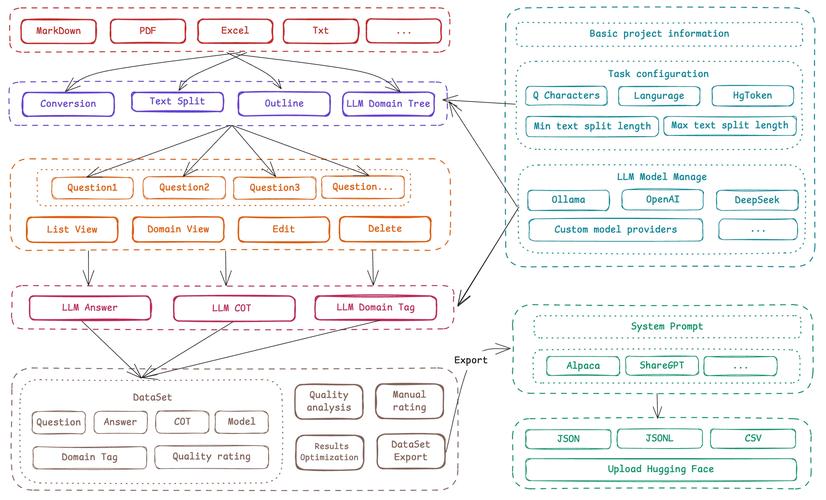
XVerse是字节跳动智能创作团队推出的新型多主体控制图像生成模型。模型在文本到图像生成领域实现对多个主体身份和语义属性(如姿势、风格、光照)的精细控制,同时保持生成图像的高质量和一致性。...
-
发布了文章 2个月前
SeedVR2 – 字节跳动推出的视频修复模型
SeedVR2是字节跳动推出的新型单步视频修复(Video Restoration, VR)模型,基于扩散模型和对抗性后训练(Adversarial Post-Training, APT)技术。模型基于自适应窗口注意力机制和...
-
发布了文章 2个月前
Seed1.6 – 字节跳动推出的通用模型系列
Seed1.6是字节跳动Seed团队推出的通用模型系列,融合多模态能力,支持256K长上下文深度推理。Seed1.6沿用Seed1.5稀疏MoE探索成果,经纯文本预训练、多模态混合持续训练、长上下文持续训练三阶段,提升文本和...
-
发布了文章 2个月前
InfiniteYou – 字节跳动开源的身份保持图像生成框架
InfiniteYou(InfU)是字节跳动智能创作团队推出的基于扩散变换器(Diffusion Transformers,如 FLUX)的身份保持图像生成框架。基于 InfuseNet 将身份特征注入扩散模型,增强身份相似...
-
发布了文章 2个月前
ContentV – 字节跳动开源的文生视频模型框架
ContentV是字节跳动开源的80亿参数文生视频模型框架。将Stable Diffusion 3.5 Large的2D-VAE替换为3D-VAE并引入3D位置编码,使图像模型快速获得视频生成能力。...






没有更多内容