

去清华联合培养怎么样
-
发布了文章 2个月前
WebRL – 清华联合智谱AI推出的自进化在线课程强化学习框架
WebRL是清华大学、智谱AI联合推出的自我进化的在线课程强化学习框架,训练使用开放大型语言模型(LLMs)的高性能网络代理。WebRL动态生成任务、结果监督奖励模型(ORM)评估任务成功与否,及自适应强化学习策略,解决训练...
-
发布了文章 2个月前
ReSyncer – 清华联合百度推出的AI视频编辑工具
ReSyncer是清华大学和百度联合推出的AI视频编辑工具,通过音频驱动生成与声音同步的高质量嘴唇动作视频。ReSyncer用Style-SyncFormer分析声音并创建3D面部模型,结合目标视频生成同步且表情丰富的虚拟人...
-
发布了文章 2个月前
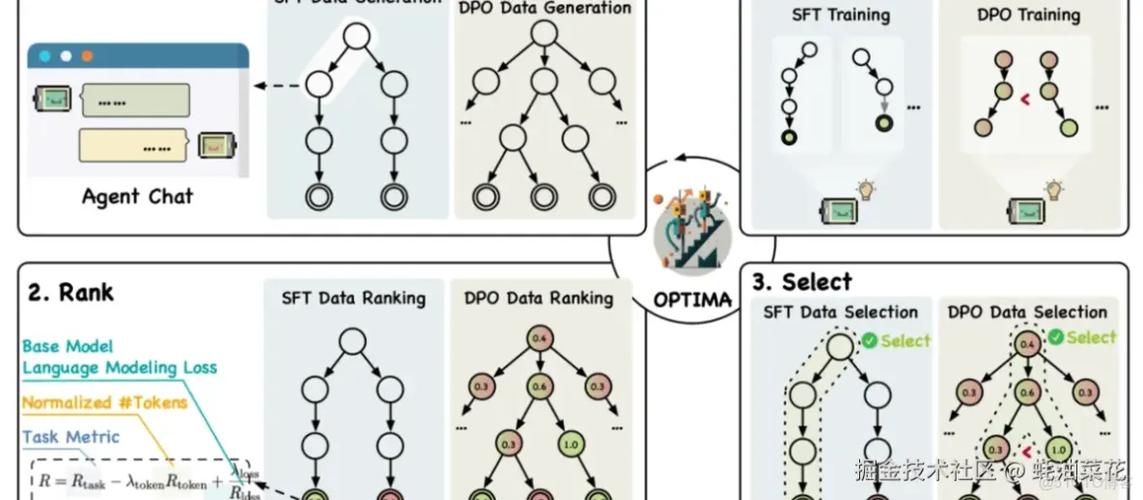
Optima – 清华联合北邮推出优化通信效率和任务有效性的训练框架
Optima是清华大学推出的优化基于大型语言模型(LLM)的多智能体系统(MAS)的框架。基于一个迭代的生成、排名、选择和训练范式,显著提高通信效率和任务效果。Optima平衡了任务性能、令牌效率和通信可读性,探索了多种强化...
-
发布了文章 2个月前
Ola – 清华联合腾讯等推出的全模态语言模型
Ola是清华大学、腾讯 Hunyuan 研究团队和新加坡国立大学 S-Lab 合作开发的全模态语言模型。通过渐进式模态对齐策略,逐步扩展语言模型支持的模态,从图像和文本开始,再引入语音和视频数据,实现对多种模态的理解。...
-
发布了文章 2个月前
HRAvatar – 清华联合IDEA推出的单目视频生成3D头像技术
HRAvatar是清华大学联合IDEA团队推出的单目视频重建技术,支持从普通单目视频中生成高质量、可重光照的3D头像。HRAvatar用可学习的形变基和线性蒙皮技术,基于精准的表情编码器减少追踪误差,提升重建质量。...
-
发布了文章 2个月前
FlexiAct – 清华联合腾讯推出的动作迁移模型
FlexiAct是清华大学和腾讯ARC实验室联合推出的新型动作迁移模型。FlexiAct能在给定目标图像的情况下,将参考视频中的动作迁移到目标主体上,在空间结构差异较大或跨域的异构场景中,实现精准的动作适配与外观一致性。...
-
发布了文章 2个月前
EMAGE – 清华联合东大等机构推出的音频生成全身共语手势框架
EMAGE(Expressive Masked Audio-conditioned GEsture modeling)是清华大学、东京大学、庆应义塾大学等机构推出的用在生成全身共语手势框架。EMAGE能根据音频和部分遮蔽的手...
-
发布了文章 2个月前
Dolphin – 清华联合海天瑞声推出的语音识别大模型
Dolphin是清华大学电子工程系语音与音频技术实验室联合海天瑞声共同推出的面向东方语言的语音大模型。支持40个东方语种的语音识别,中文语种涵盖22种方言(含普通话),能精准识别不同地区的语言特点。...
-
发布了文章 2个月前
BizGen – 清华大学联合微软推出的AI信息图生成工具
BizGen是清华大学和微软研究院联合推出的AI信息图生成工具,专注于文章级别的视觉文本渲染。能一键将长篇文章内容转化为专业级的信息图和幻灯片,解决传统工具在处理长文本时文字模糊、排版混乱的问题。...
-
发布了文章 2个月前
APB – 清华联合腾讯等机构推出的分布式长上下文推理框架
APB(Accelerating Distributed Long-Context Inference by Passing Compressed Context Blocks across GPUs)是清华大学等机构联合提...











没有更多内容