

字节跳动 .net
-
发布了文章 2个月前
XVerse – 字节跳动推出的多主体控制图像生成模型
XVerse是字节跳动智能创作团队推出的新型多主体控制图像生成模型。模型在文本到图像生成领域实现对多个主体身份和语义属性(如姿势、风格、光照)的精细控制,同时保持生成图像的高质量和一致性。...
-
发布了文章 2个月前
X-baidu09Portrait 2 – 字节跳动推出的单图驱动视频生成模型
X-Portrait 2是字节跳动智能创作团队推出的单图视频驱动技术,基于一张静态照片和一段驱动视频生成高质量、电影级视频。X-Portrait 2保留原图身份特征,准确捕捉细微表情和情绪,实现跨风格动作迁移,适用于写实人像...
-
发布了文章 2个月前
VeOmni – 字节跳动开源的全模态PyTorch原生训练框架
VeOmni 是字节跳动 Seed 团队开源的全模态分布式训练框架,基于 PyTorch 设计。VeOmni 以模型为中心,将分布式并行逻辑与模型计算解耦,支持灵活组合多种并行策略(如 FSDP、SP、EP),能高效扩展至超...
-
发布了文章 2个月前
SuperEdit – 字节跳动等机构推出的图像编辑方法
SuperEdit是字节跳动智能创作团队和佛罗里达中央大学计算机视觉研究中心联合推出的指令引导图像编辑方法,基于优化监督信号提高图像编辑的精度和效果。SuperEdit基于纠正编辑指令,与原始图像和编辑图像对更准确地对齐,引...
-
发布了文章 2个月前
Phantom – 字节跳动推出的主体一致视频生成框架
Phantom是字节跳动智能创作团队推出的用在主体一致视频生成(Subject-to-Video, S2V)的框架。基于跨模态对齐技术,结合文本和图像提示,从参考图像中提取主体元素并生成与文本描述一致的视频内容。...
-
发布了文章 2个月前
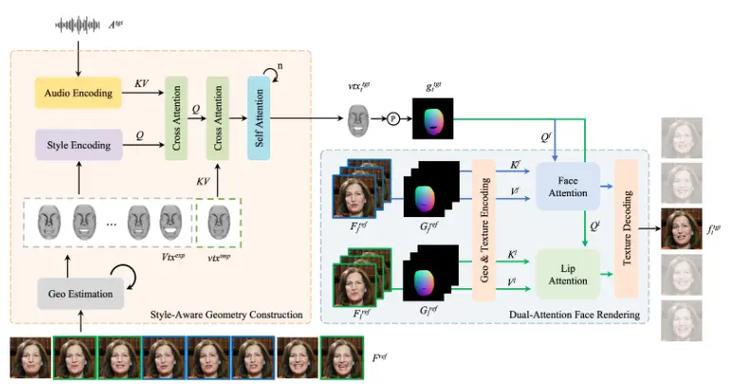
PersonaTalk – 字节跳动推出的实现高保真和个性化视觉配音框架
PersonaTalk是字节跳动推出的基于注意力机制的两阶段框架,用在实现高保真度和个性化的视觉配音。PersonaTalk能在合成与目标音频精准唇形同步的视频的同时,保留说话者的独特说话风格和面部细节。...
-
发布了文章 2个月前
Infinity – 字节跳动推出的高分辨率图像生成模型
Infinity是字节跳动推出的基于位级自回归建模的视觉生成模型,能根据语言指令生成高分辨率、逼真的图像。Infinity通过无限词汇量的标记器、分类器和位自纠正机制,显著提升图像生成的细节和质量,超越现有的顶级扩散模型,生...
-
发布了文章 2个月前
InfiniteYou – 字节跳动开源的身份保持图像生成框架
InfiniteYou(InfU)是字节跳动智能创作团队推出的基于扩散变换器(Diffusion Transformers,如 FLUX)的身份保持图像生成框架。基于 InfuseNet 将身份特征注入扩散模型,增强身份相似...
-
发布了文章 2个月前
ImmerseGen – 字节跳动联合浙大推出的3D世界生成框架
ImmerseGen是字节跳动的PICO团队和浙江大学联合推出的创新3D世界生成框架。框架根据用户输入的文字提示,基于Agent引导的资产设计和排列,生成带有alpha纹理的紧凑Agent,创建全景3D世界。...
-
发布了文章 2个月前
HeadGAP – 字节跳动推出的3D头像生成模型
HeadGAP是字节跳动和上海科技大学共同推出的3D头像生成模型,仅用少量图片快速生成逼真的3D头像。采用先验学习和个性化创建阶段的框架,基于大规模多视角动态数据集导出的3D头部先验信息。通过高斯Splatting自动解码网...
-
发布了文章 2个月前
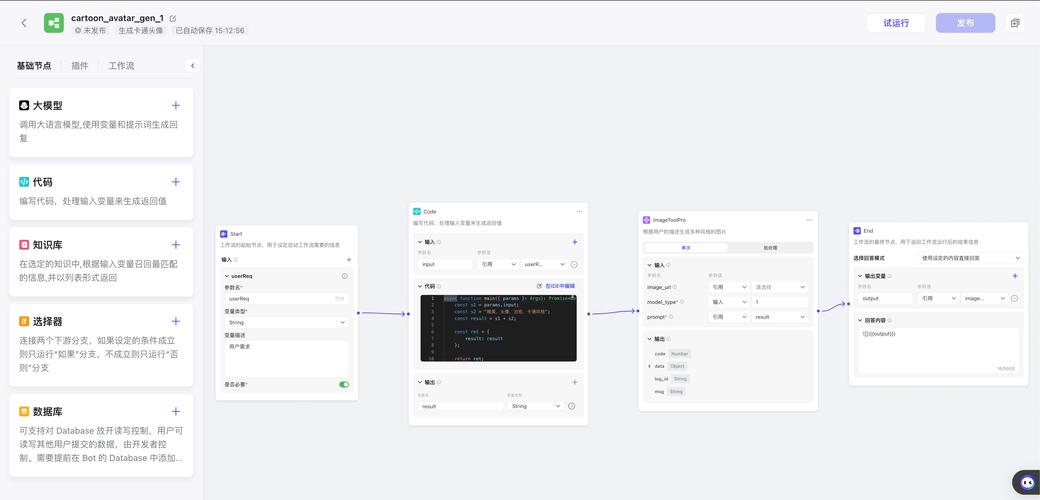
FlowGram – 字节跳动开源的可视化工作流搭建引擎
FlowGram是字节跳动开源的基于节点编辑的可视化工作流搭建引擎,帮助开发者快速构建固定布局或自由连线布局的工作流。支持两种布局模式:固定布局适合顺序工作流和决策树,提供层次化结构和灵活的分支、复合节点;自由布局支持节点自...
-
发布了文章 2个月前
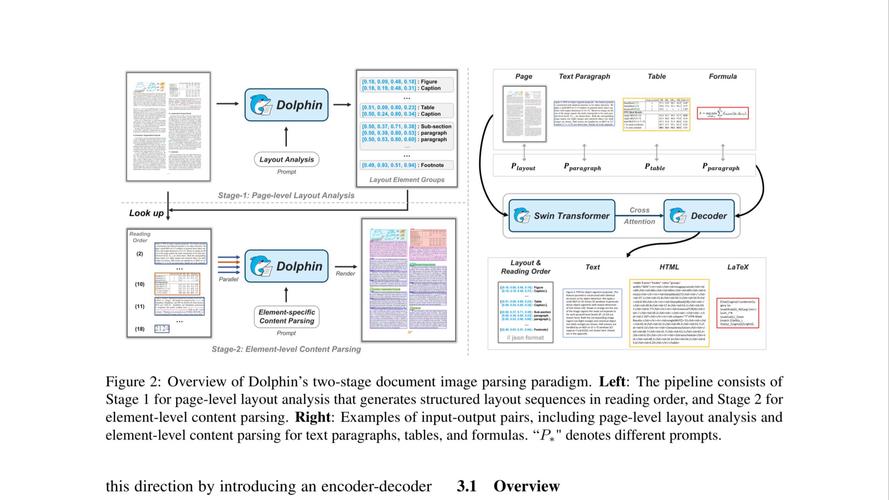
Dolphin – 字节跳动开源的文档解析大模型
Dolphin 是字节跳动开源的轻量级、高效的文档解析大模型。基于先解析结构后解析内容的两阶段方法,第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。...
-
发布了文章 2个月前
快讯:字节跳动否认120亿美元投资AI
...
-
发布了文章 2个月前
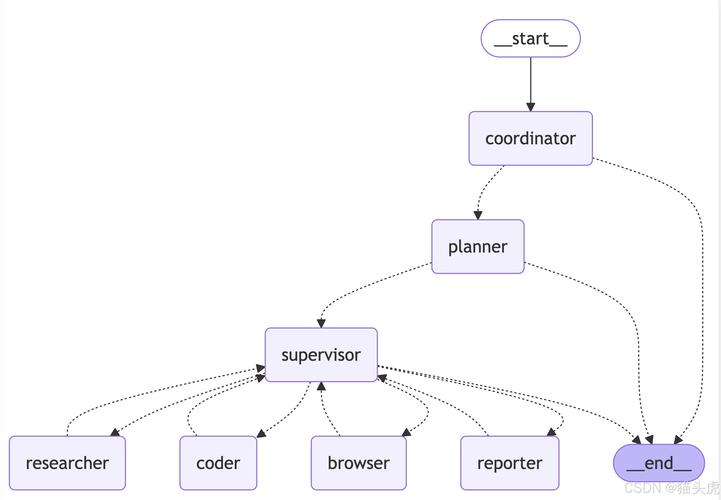
DeerFlow – 字节跳动开源的深度研究框架
DeerFlow 是字节跳动开源的深度研究框架,能帮助用户高效完成复杂的研究任务。DeerFlow结合语言模型与多种工具,如网络搜索、爬虫和 Python 执行,能快速生成全面的研究报告、播客和演示文稿。...
-
发布了文章 2个月前
ContentV – 字节跳动开源的文生视频模型框架
ContentV是字节跳动开源的80亿参数文生视频模型框架。将Stable Diffusion 3.5 Large的2D-VAE替换为3D-VAE并引入3D位置编码,使图像模型快速获得视频生成能力。...

















没有更多内容