字节对齐规则
-
发布了文章 2个月前
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果
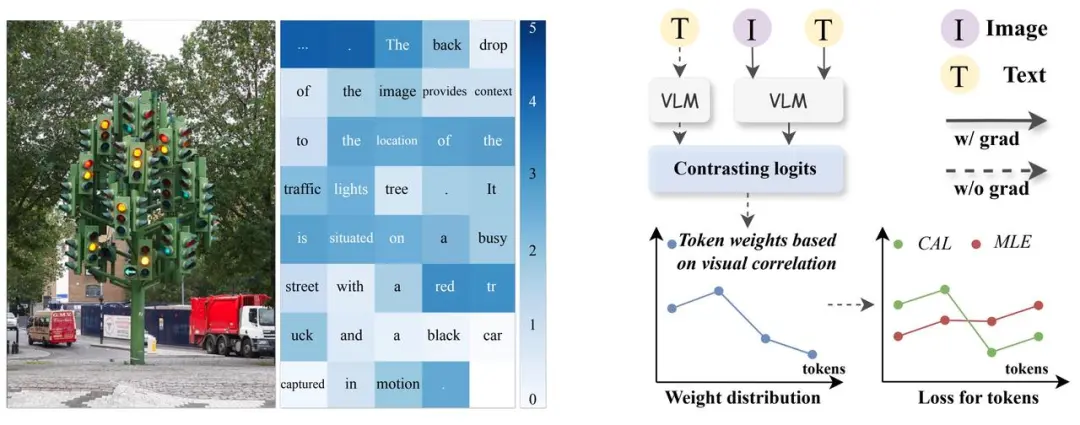
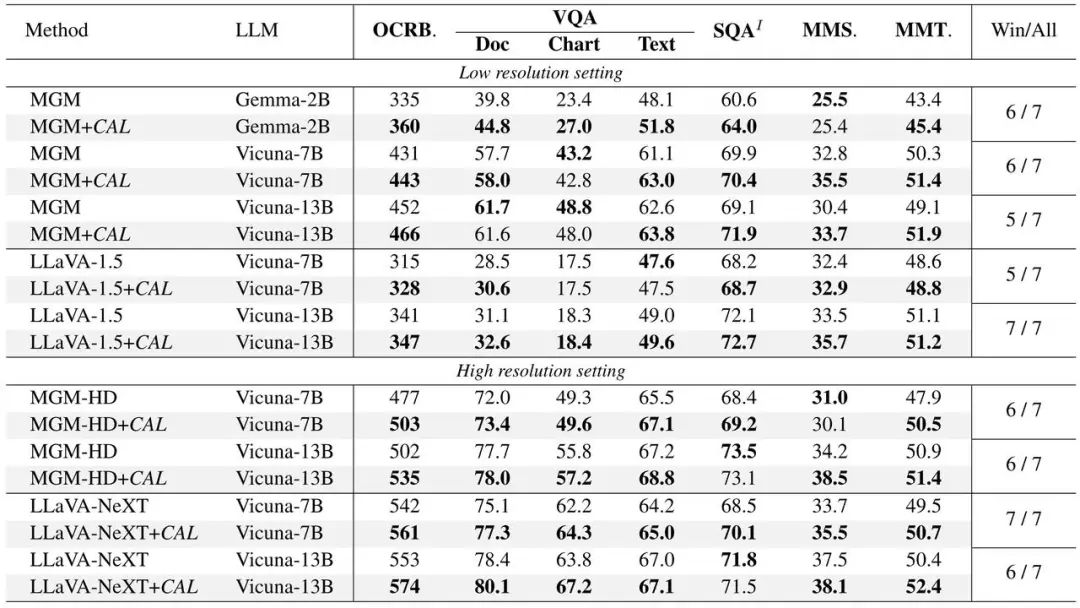
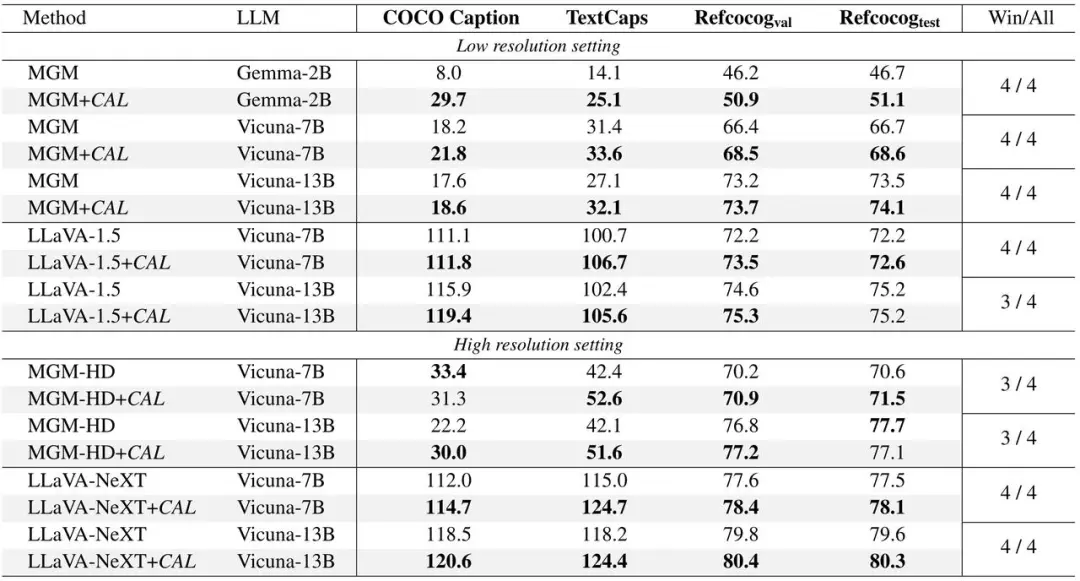
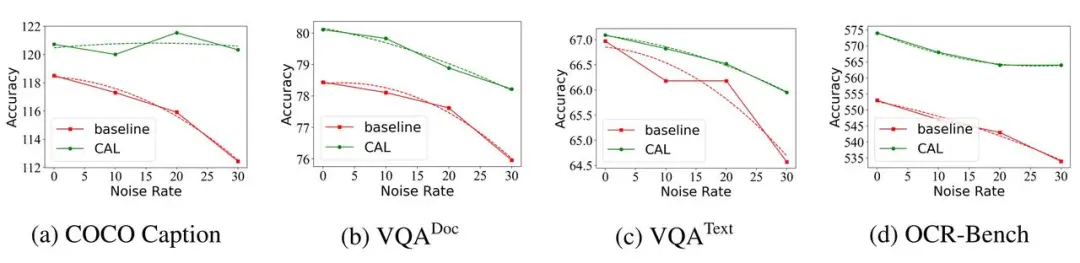
字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果 当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方...
没有更多内容



字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果 当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方...


没有更多内容