gpt升高
-
发布了文章 2个月前
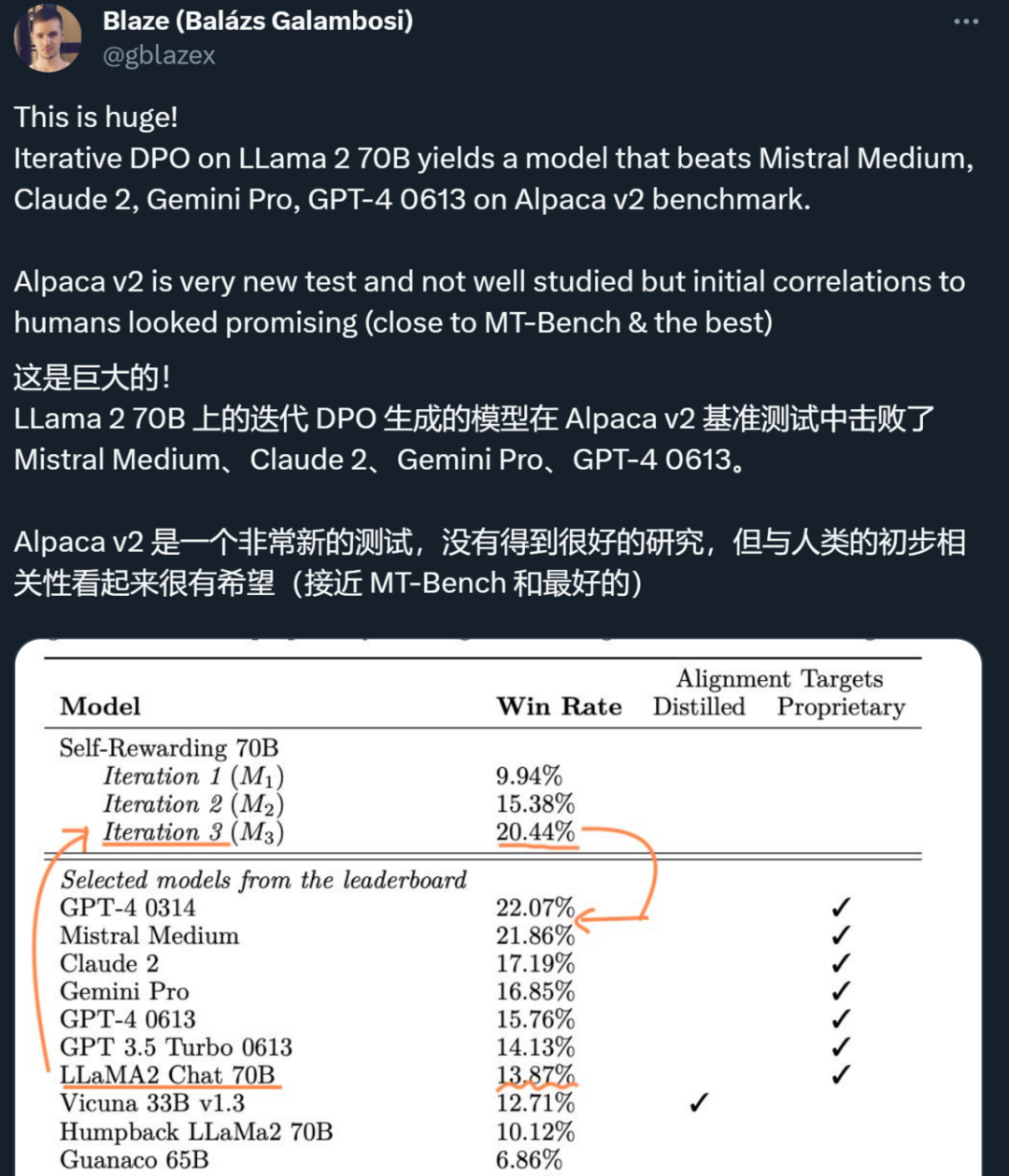
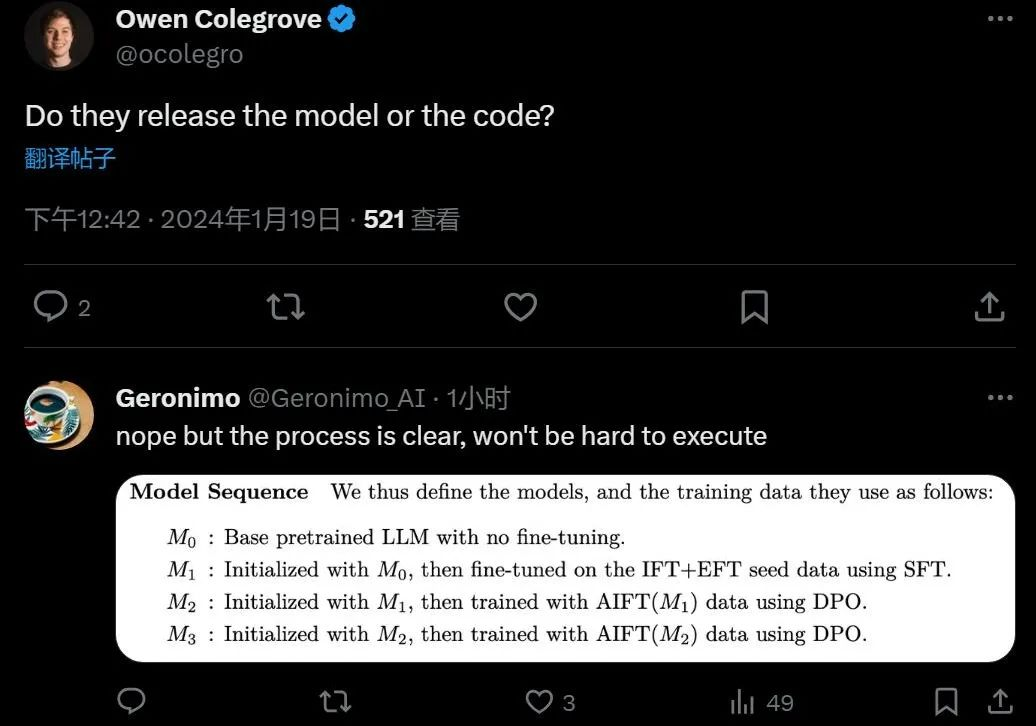
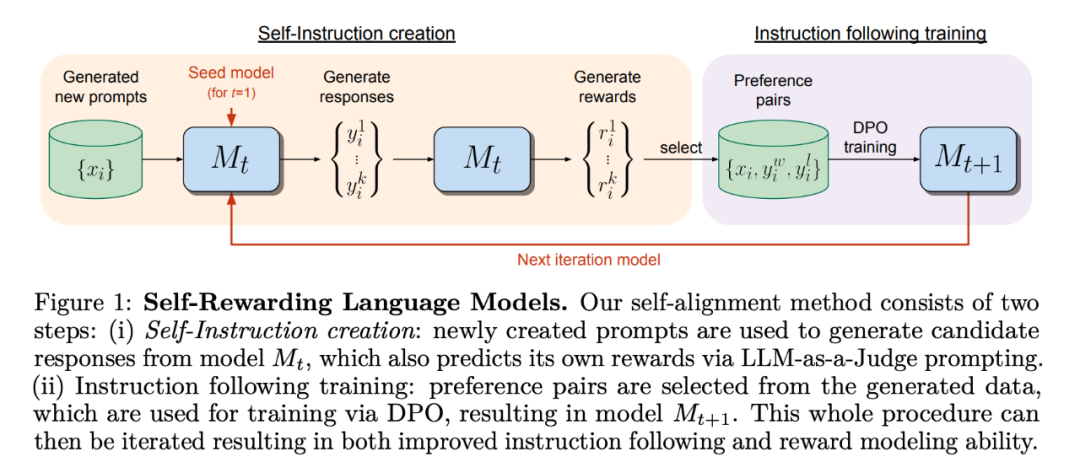
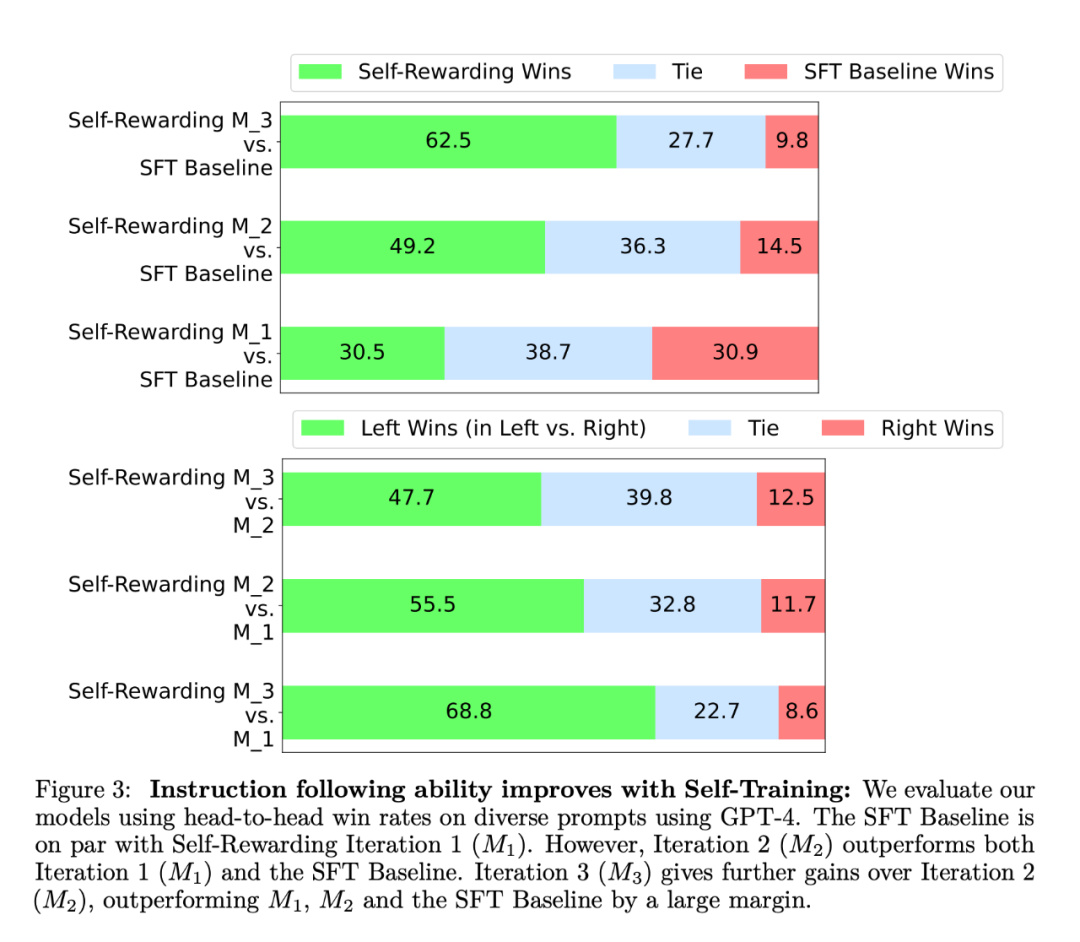
大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4
大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4 人工智能的反馈(AIF)要代替 RLHF 了?大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,...
没有更多内容



大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4 人工智能的反馈(AIF)要代替 RLHF 了?大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,...


没有更多内容