豆包造型做法
-
发布了文章 2个月前
豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务
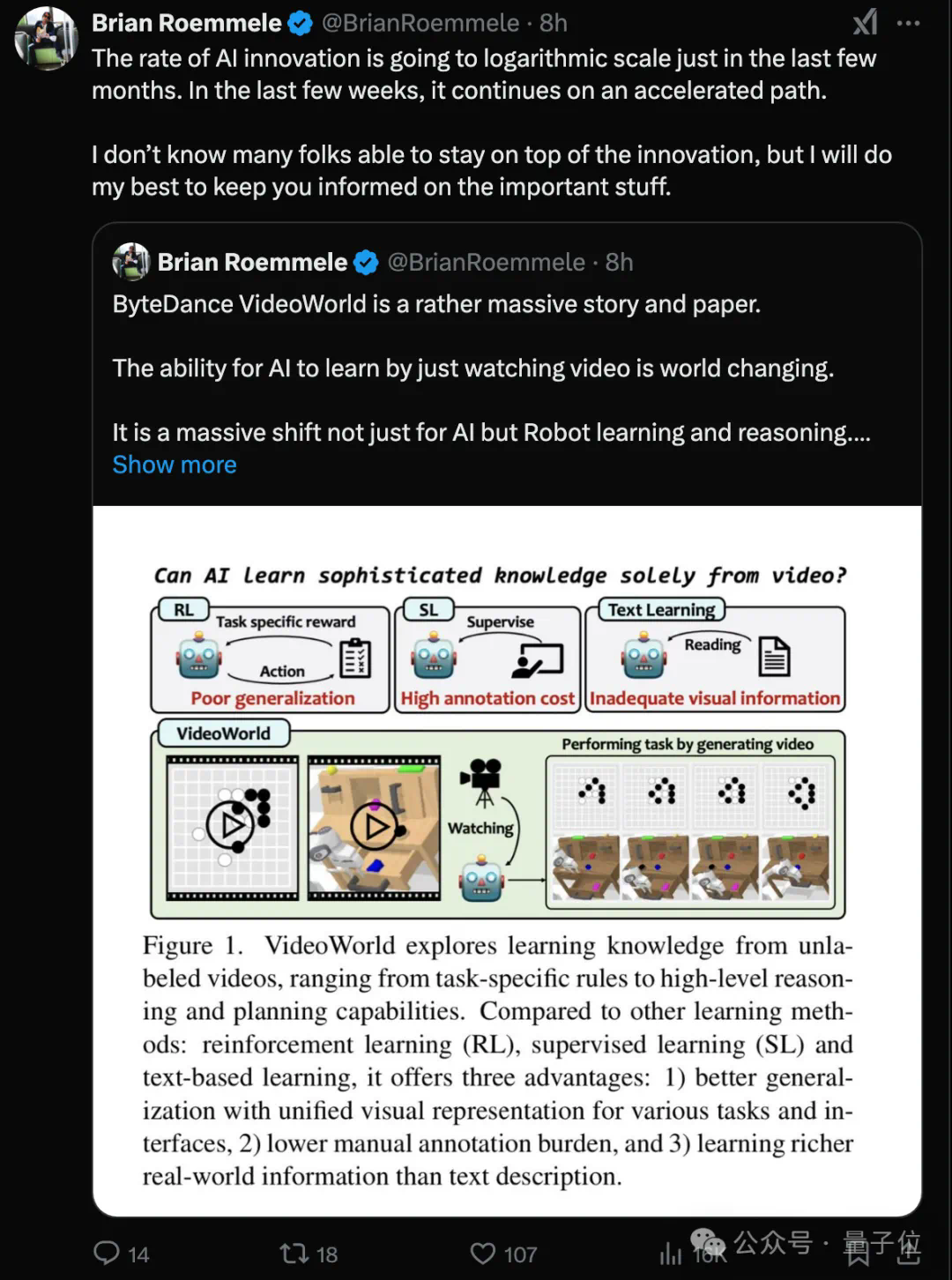
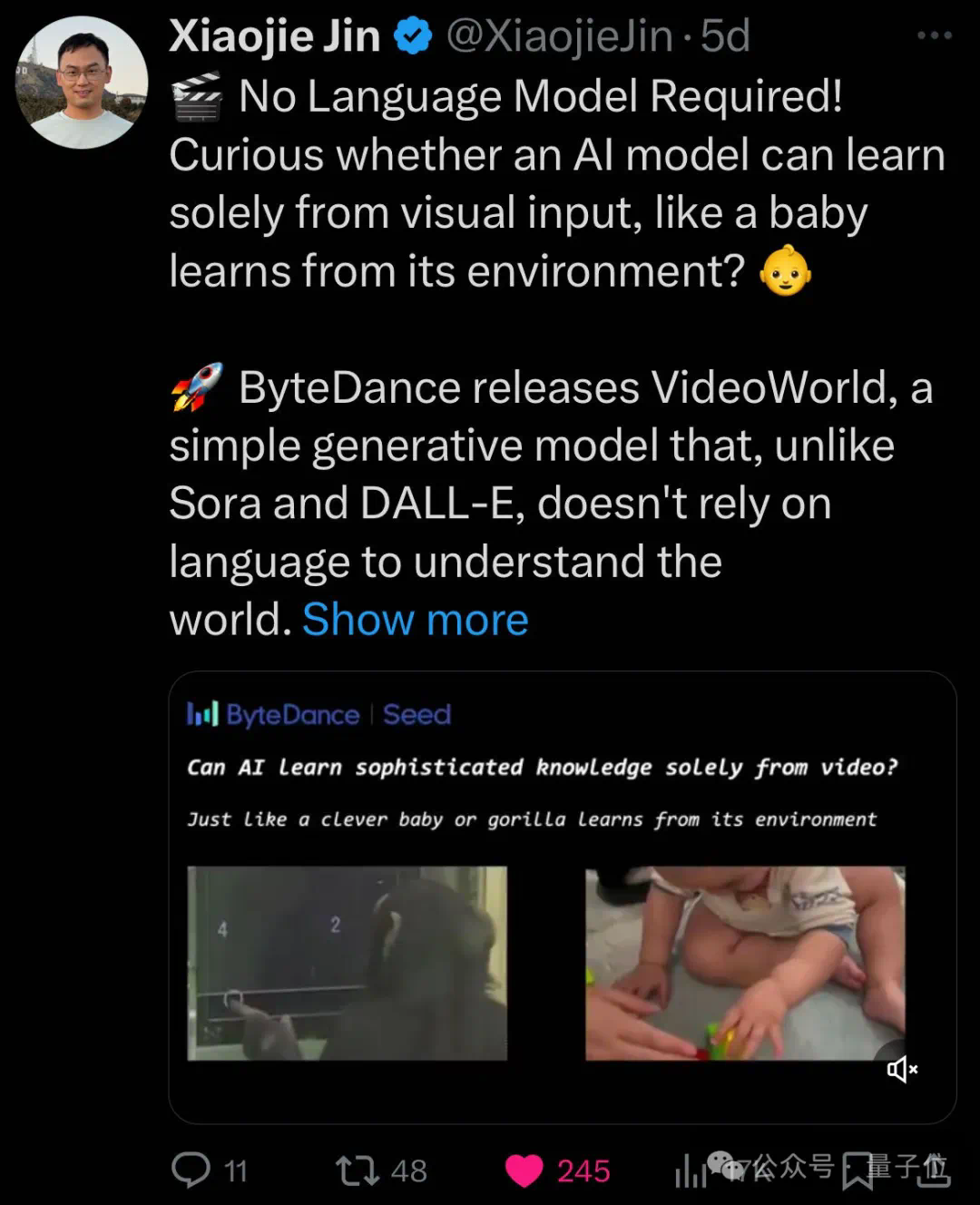
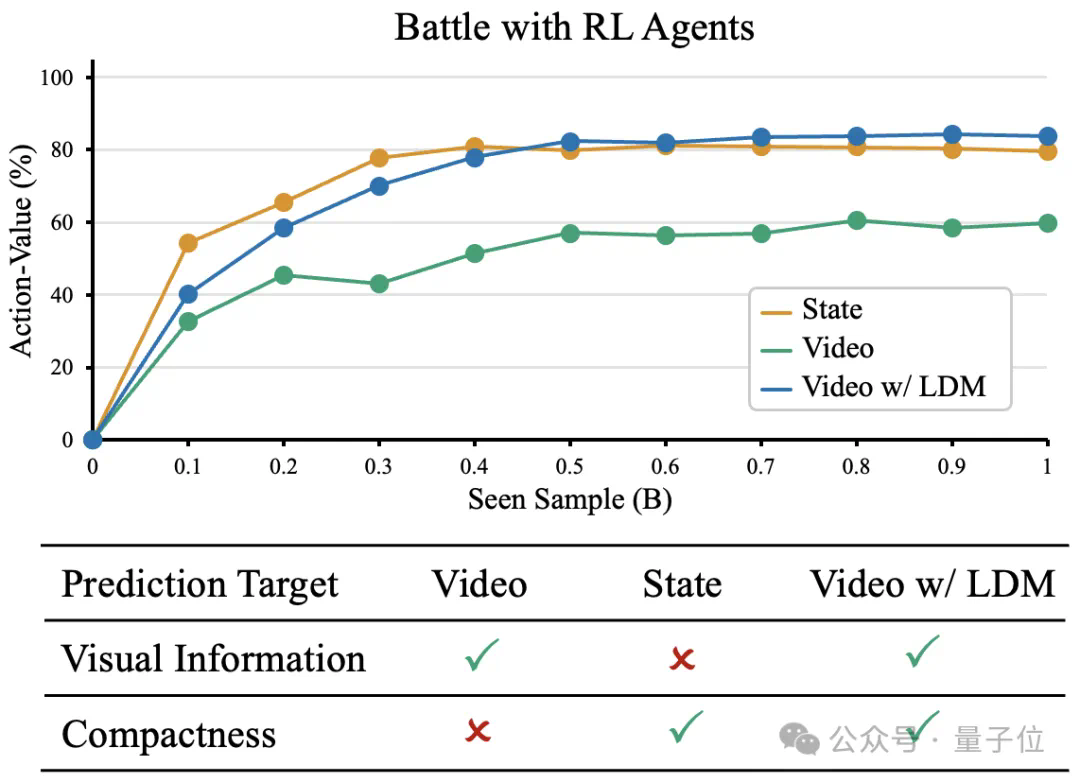
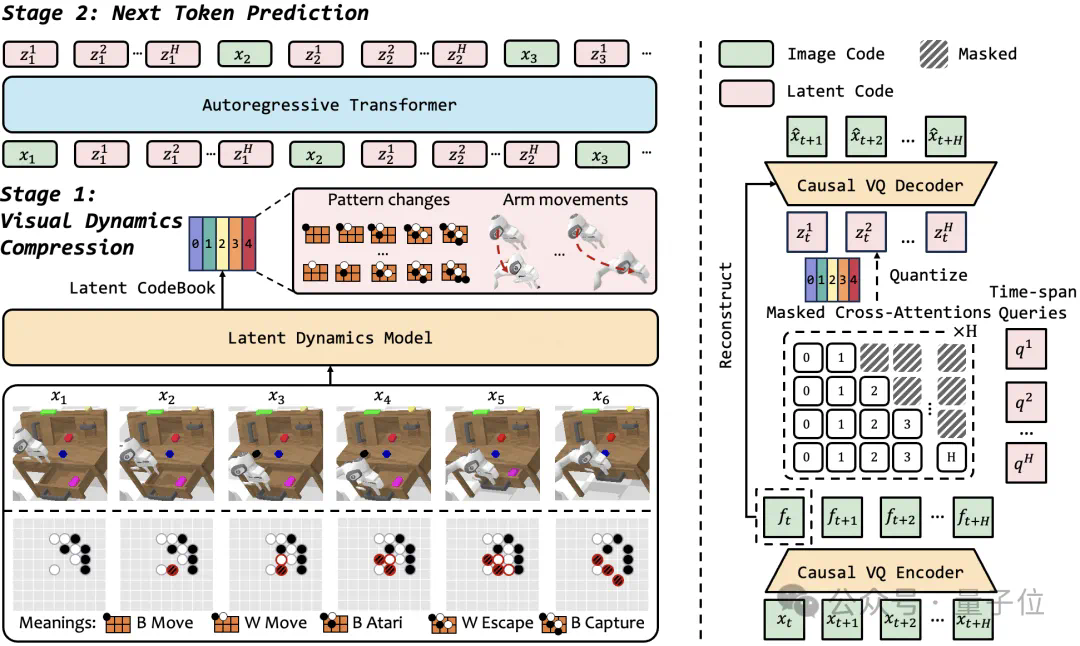
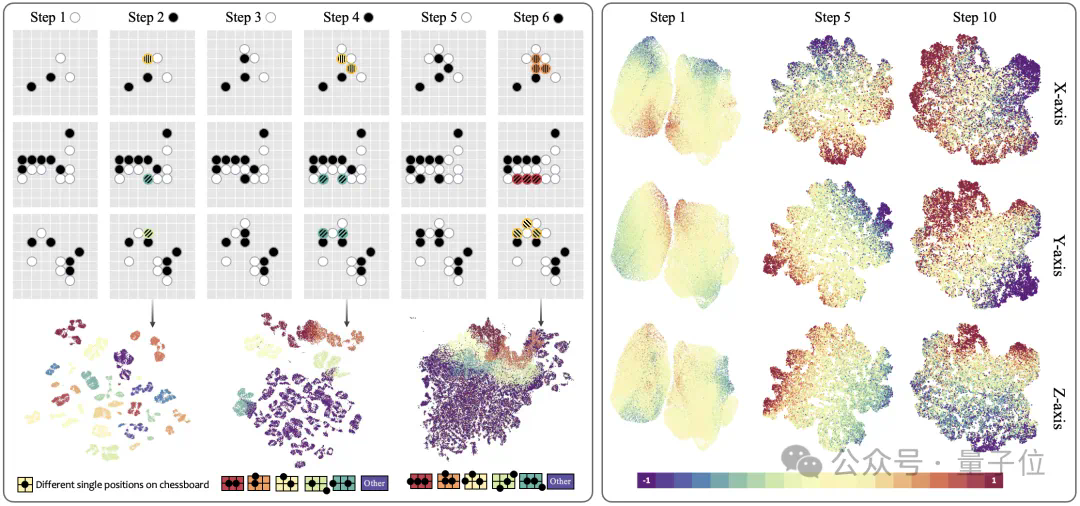
豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务 现有的视频生成模型,大多依赖语言或标签数据学习知识,很少涉及纯视觉信号的学习,比如Sora。然而,语言并不能捕捉真实世界中的所有知识,例如,折纸、打领...
没有更多内容



豆包团队视频生成新突破:无需语言模型,仅凭“视觉”就能学习复杂任务 现有的视频生成模型,大多依赖语言或标签数据学习知识,很少涉及纯视觉信号的学习,比如Sora。然而,语言并不能捕捉真实世界中的所有知识,例如,折纸、打领...

没有更多内容