

gpt超高
-
发布了文章 2个月前
大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4
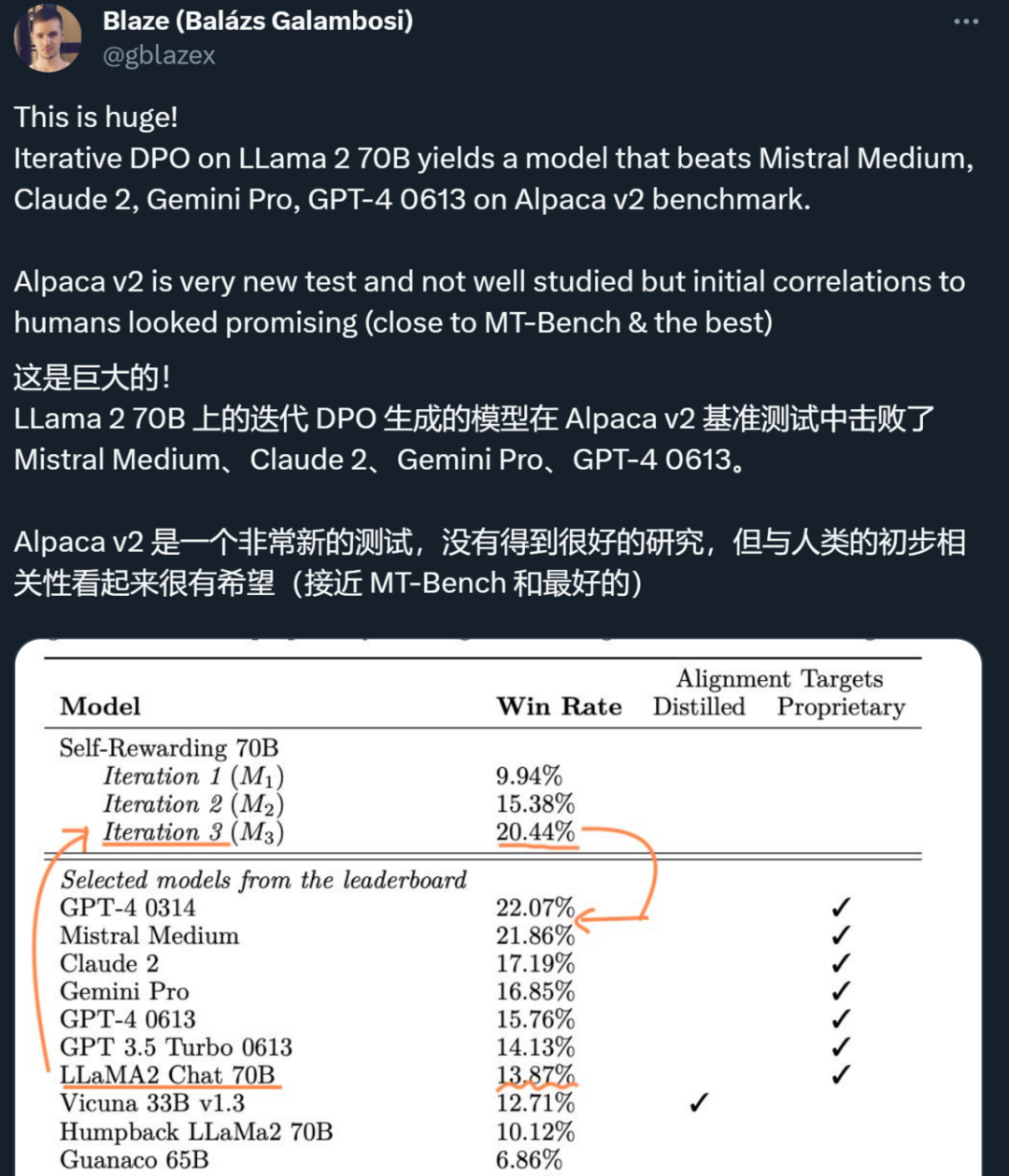
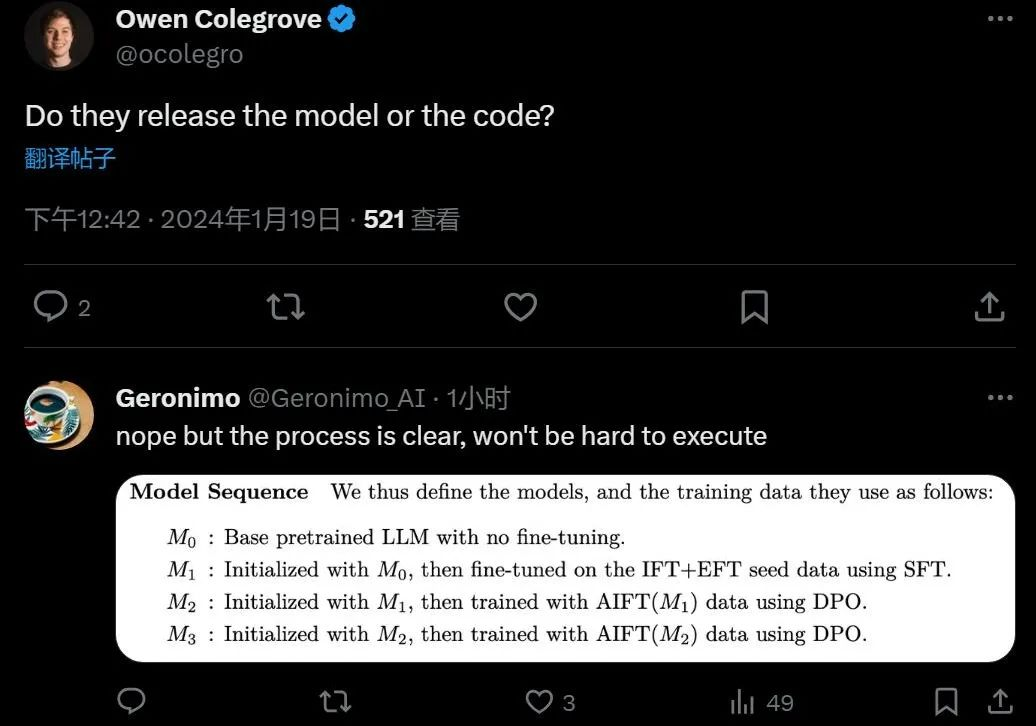
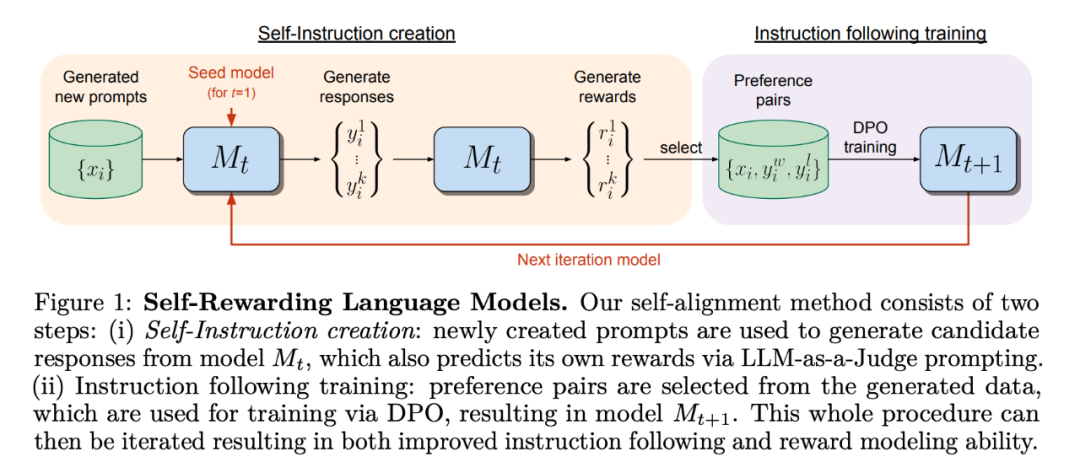
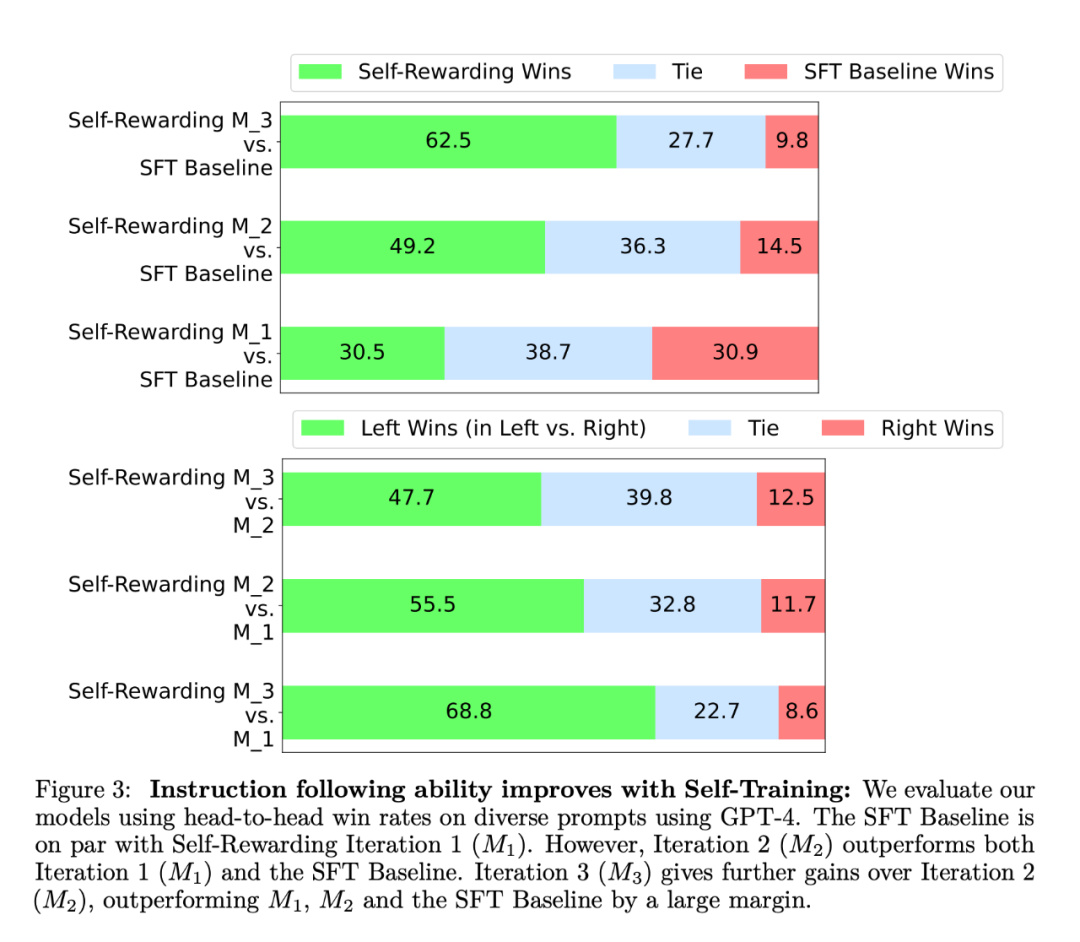
大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4 人工智能的反馈(AIF)要代替 RLHF 了?大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,...
-
发布了文章 2个月前
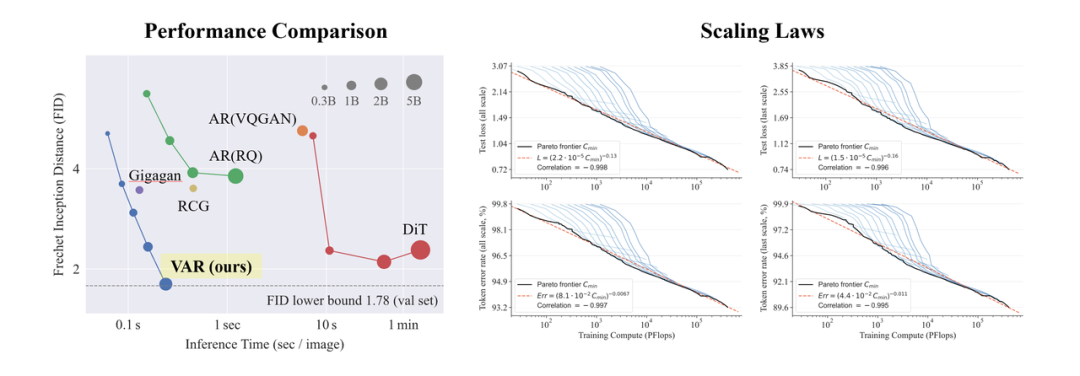
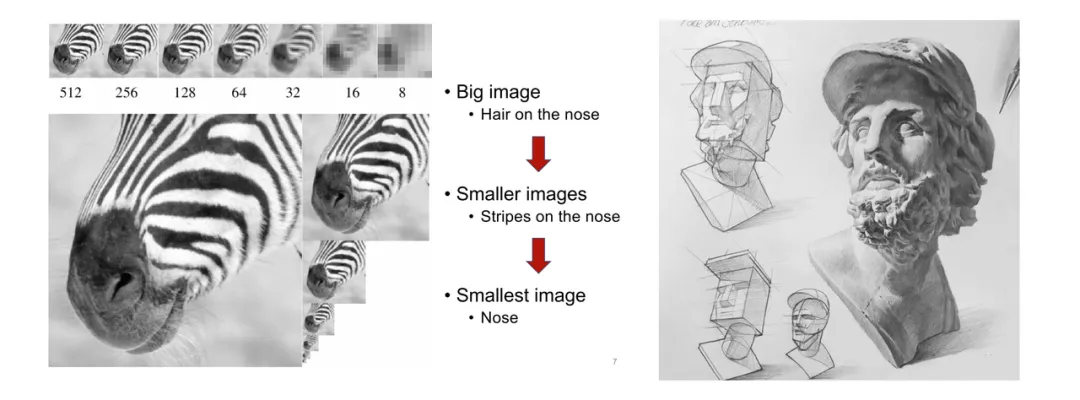
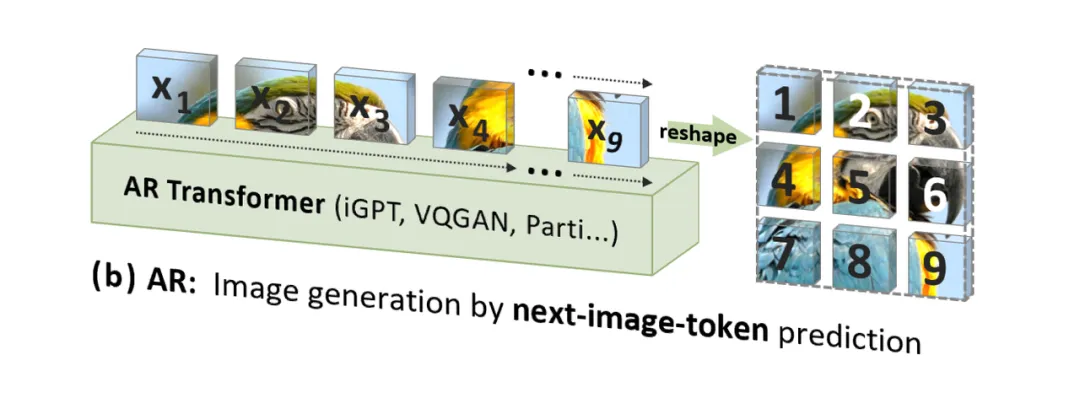
GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式
GPT超越扩散、视觉生成Scaling Law时刻!北大&字节提出VAR范式 新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了!使 GPT 风格的自回归模型在...




没有更多内容