模态动能
-
发布了文章 2个月前
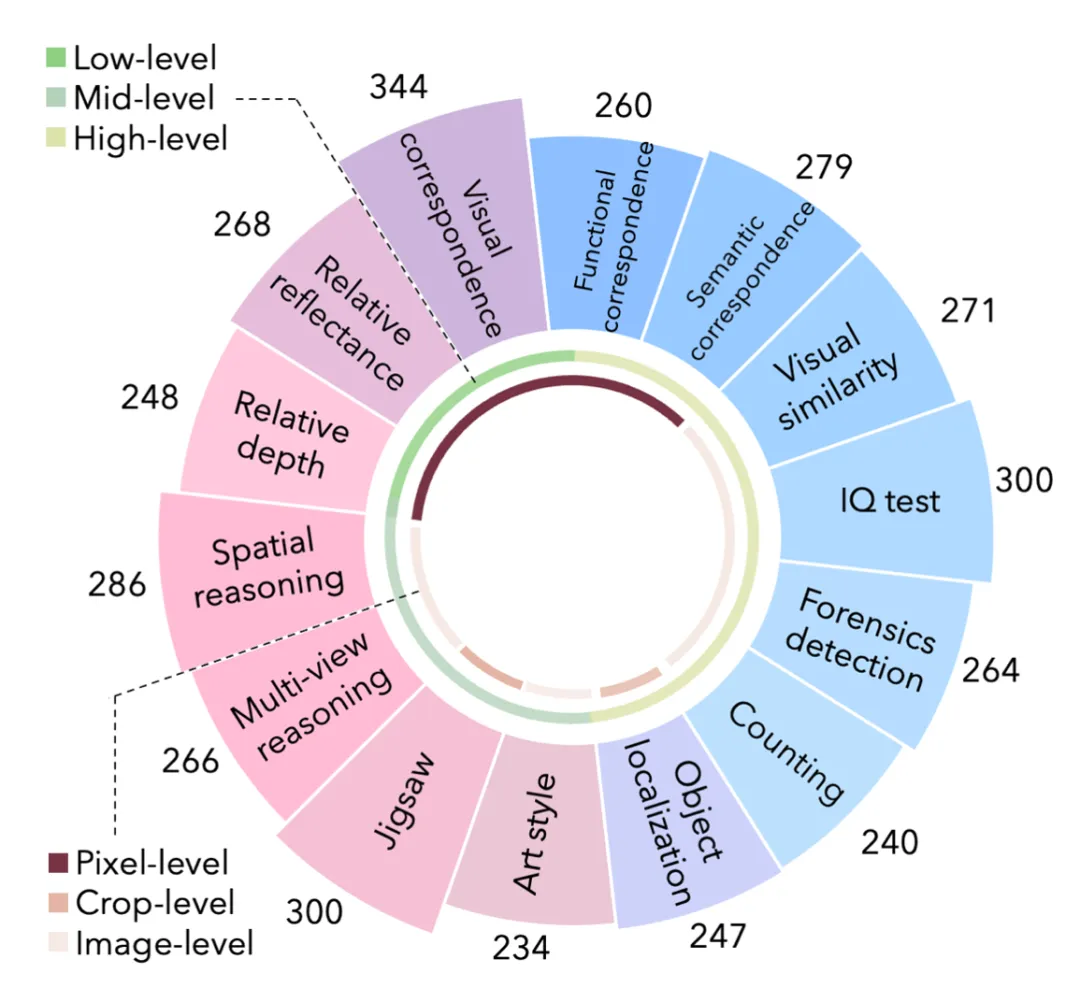
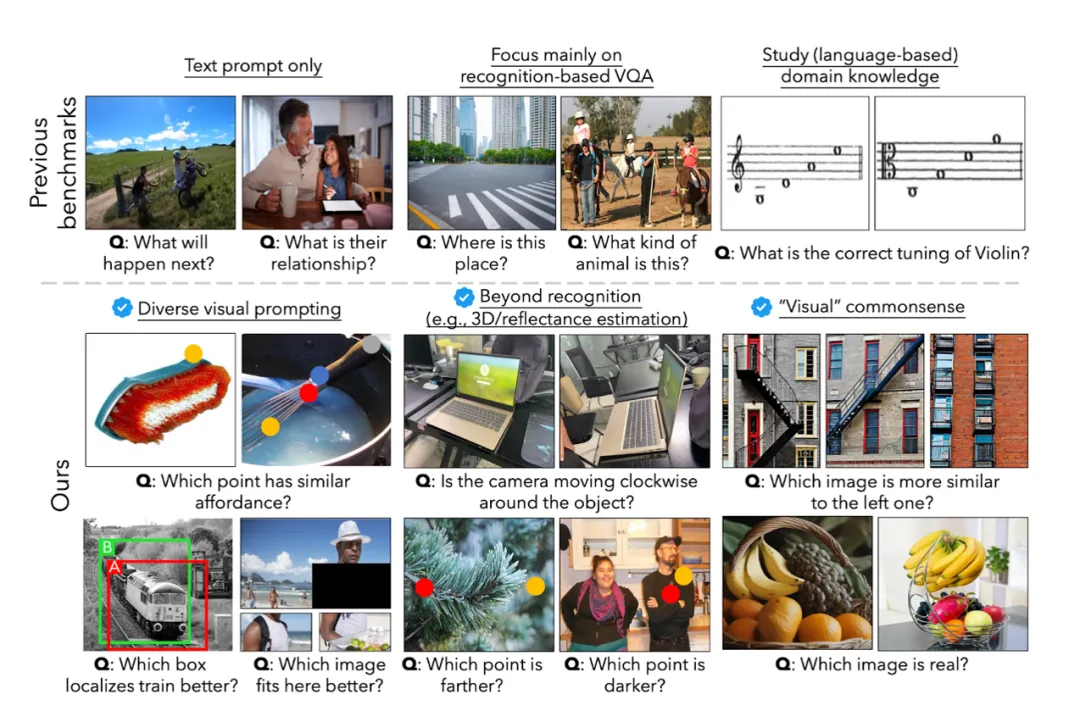
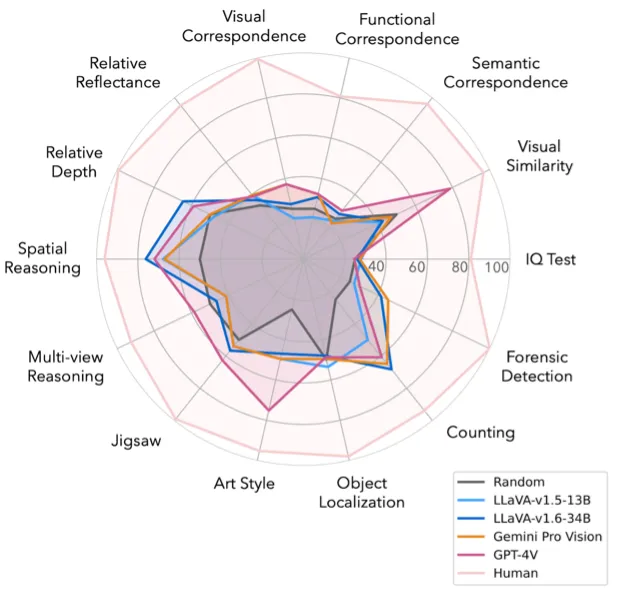
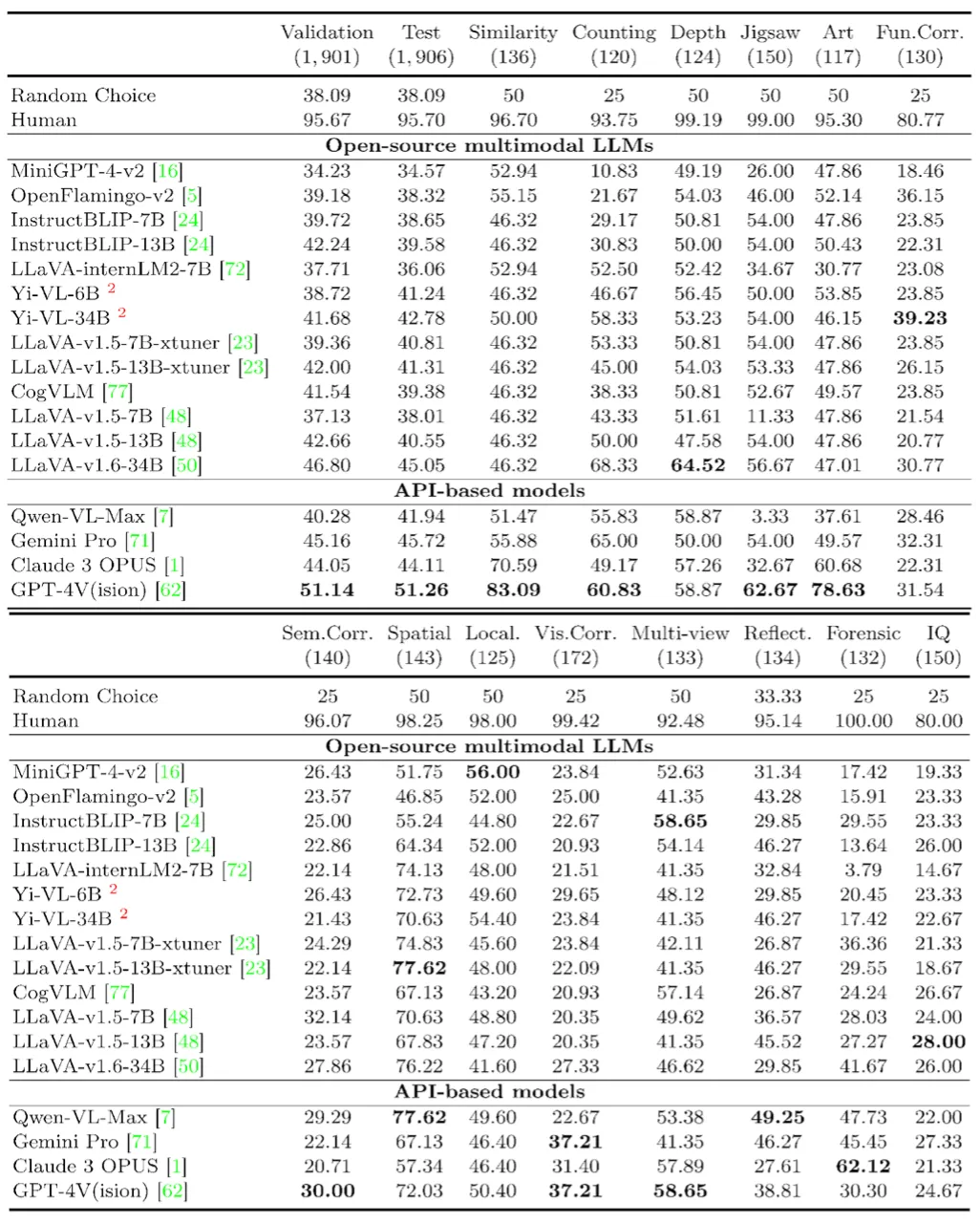
14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力?
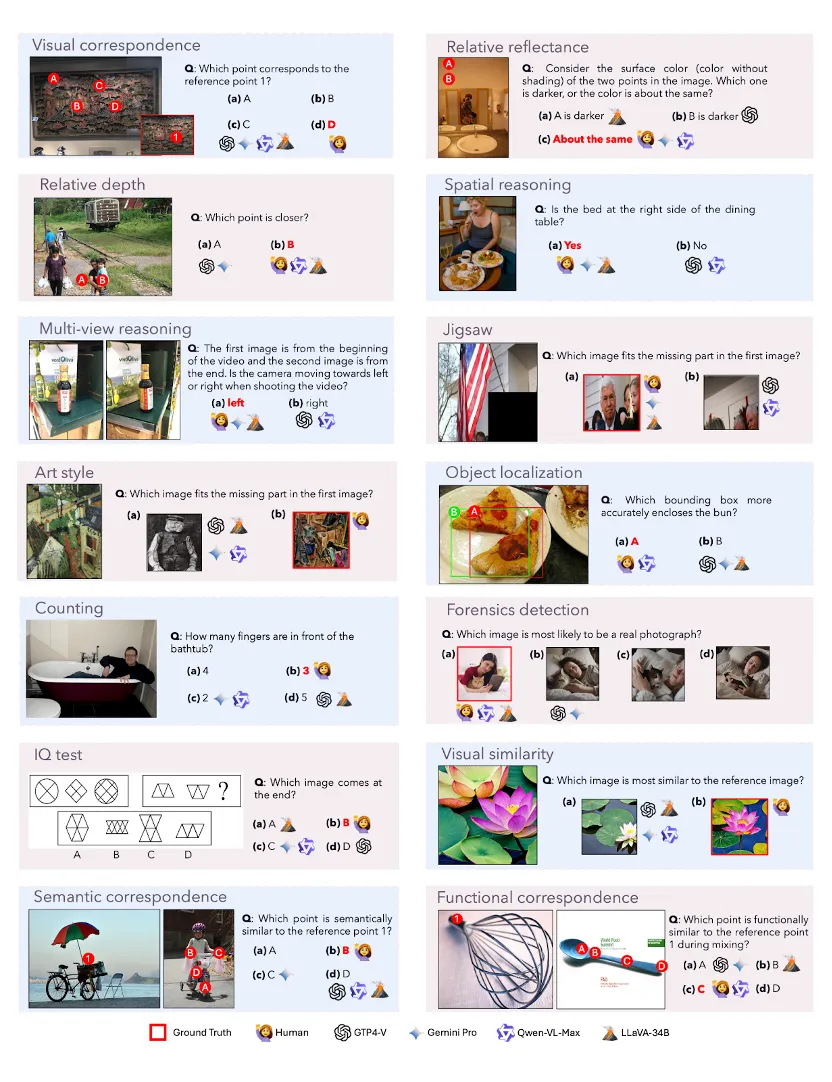
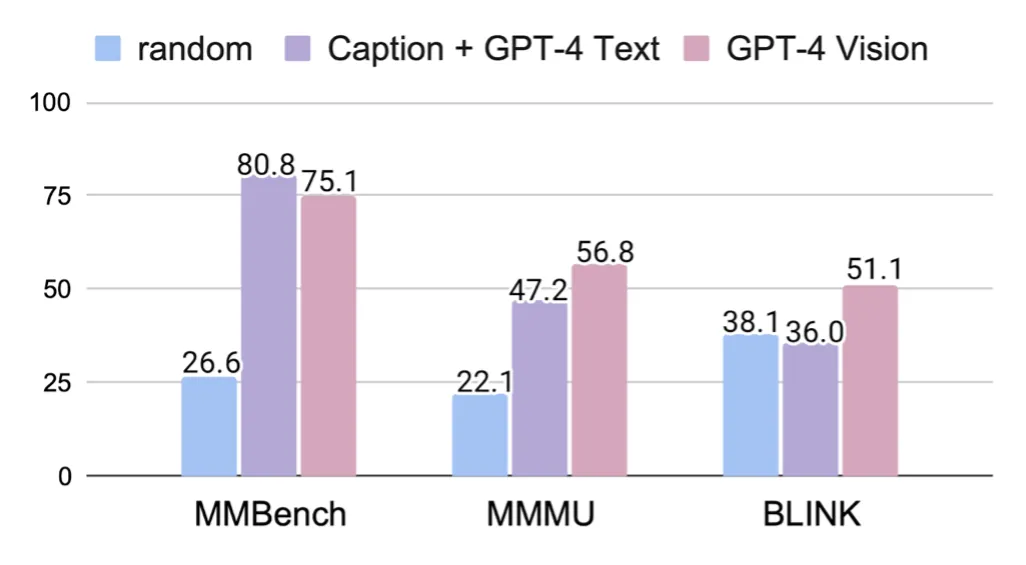
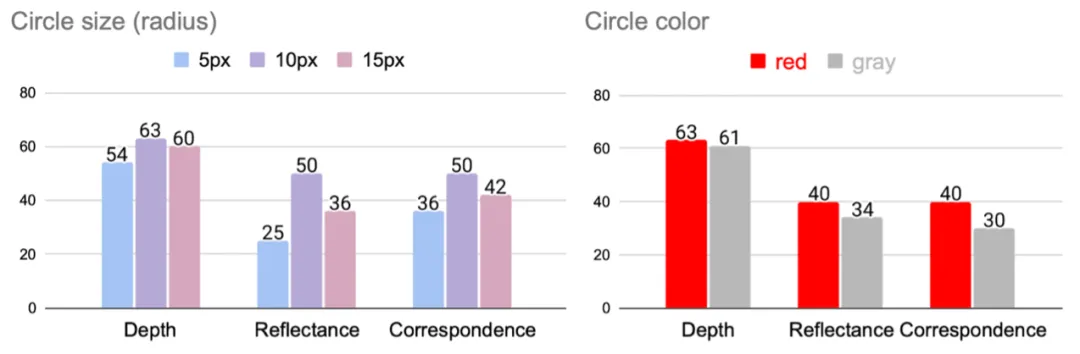
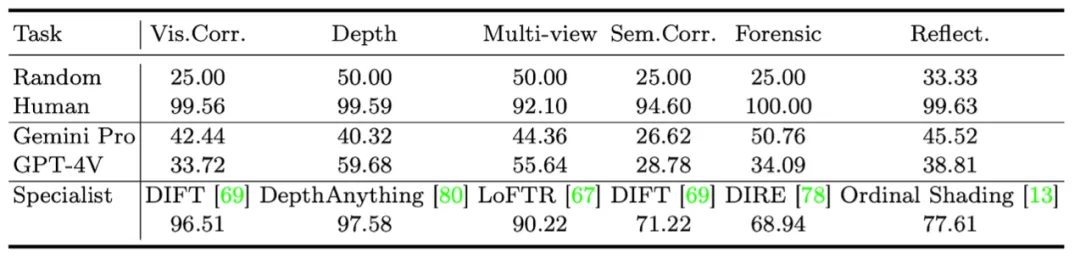
14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力? 2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)...
没有更多内容



14 项任务测下来,GPT4V、Gemini等多模态大模型竟都没什么视觉感知能力? 2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)...


没有更多内容