推理英伟突破怎么玩
-
发布了文章 2个月前
英伟达揭示RL Scaling魔力!训练步数翻倍=推理能力质变,小模型突破推理极限
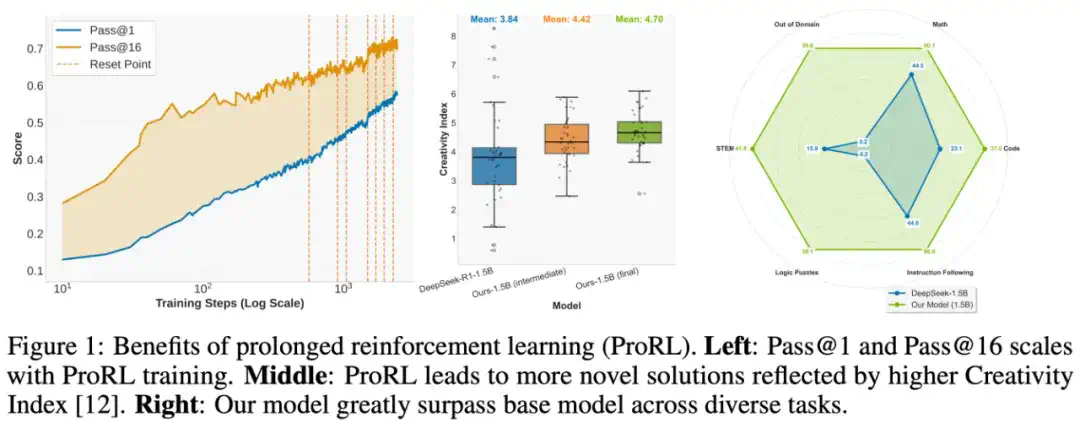
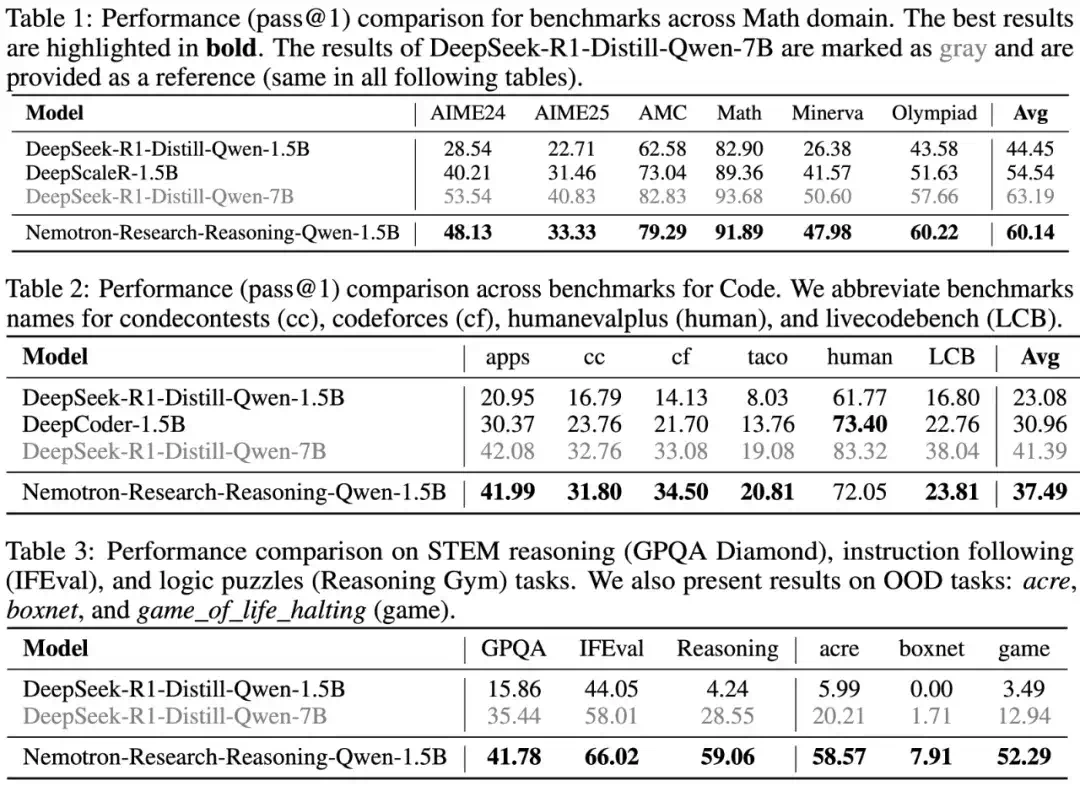
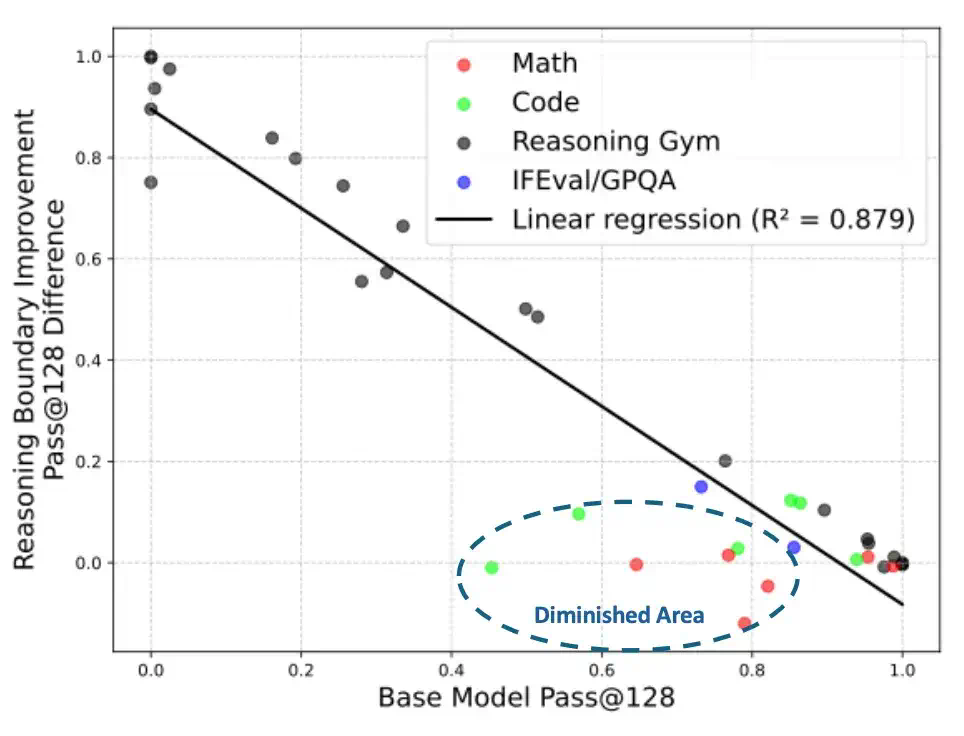
英伟达揭示RL Scaling魔力!训练步数翻倍=推理能力质变,小模型突破推理极限 过去的研究多数持悲观态度:认为 RL 带来的收益非常有限,有时甚至会让模型「同质化」加重,失去多样性。然而,来自英伟达的这项研究指出,...
没有更多内容



英伟达揭示RL Scaling魔力!训练步数翻倍=推理能力质变,小模型突破推理极限 过去的研究多数持悲观态度:认为 RL 带来的收益非常有限,有时甚至会让模型「同质化」加重,失去多样性。然而,来自英伟达的这项研究指出,...


没有更多内容