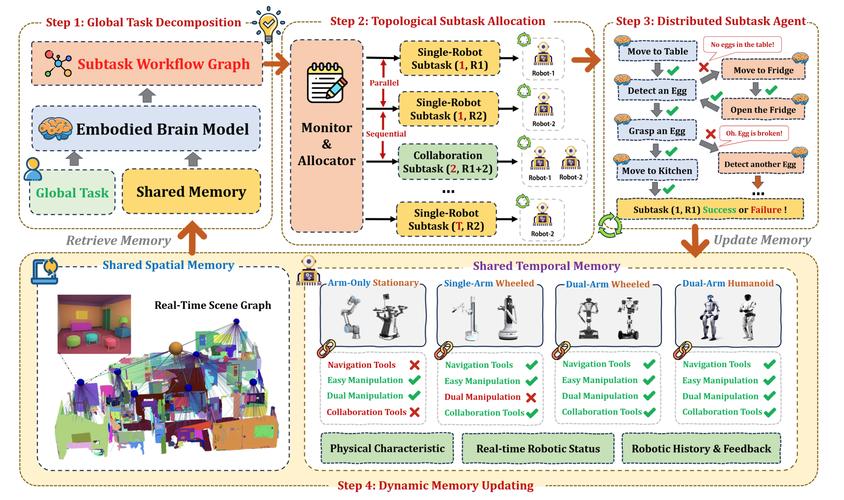
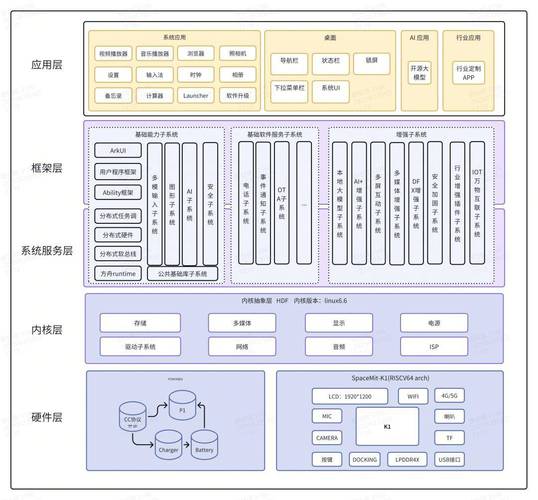
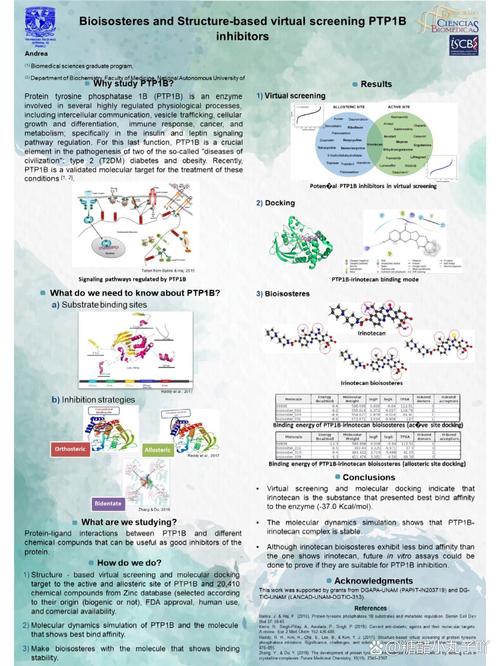
AI工具
发布文章-
发布了文章 2个月前
PearAI – 开源的AI代码编辑器,基于VSCode开发直接与代码库对话
PearAI 是一个开源的 AI 驱动的代码编辑器,基于 Visual Studio Code (VSCode 开发。PearAI 集成AI技术,减少编程工作量提高开发效率。PearAI 支持开发者直接与代码库对话,提出问...
-
发布了文章 2个月前
PartGen – 牛津大学联合 Meta AI 推出的3D对象生成和重建框架
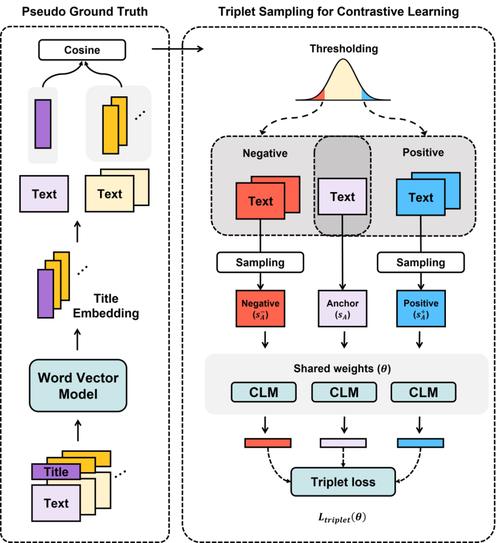
PartGen是先进的3D对象生成和重建框架,是牛津大学的视觉几何小组和Meta AI共同推出的。PartGen能识别并生成由有意义部分组成的3D对象,3D对象能基于文本提示、图像或现有的3D模型生成。PartGen用多视图...
-
发布了文章 2个月前
PartEdit – KAUST推出的细粒度图像编辑方法
PartEdit是KAUST推出基于预训练扩散模型的细粒度图像编辑方法。PartEdit基于优化特定的文本标记(称为“部分标记”),让扩散模型精准定位和编辑图像中对象的各个部分。这些部分标记学习与对象部分对应的非二进制掩码,...
-
发布了文章 2个月前
PartCrafter – AI 3D生成模型,支持多部件联合生成
PartCrafter 是先进的3D生成模型,能从单张RGB图像中生成多个语义明确且几何形态各异的3D网格。通过组合潜在空间表示每个3D部件,使用层次化注意力机制在部件内部和部件之间传递信息,确保生成的3D模型具有全局一致性...
-
发布了文章 2个月前
Parler-baidu09TTS – Hugging Face开源的文本转语音模型
Parler-TTS是由Hugging Face推出的一款开源的文本到语音(TTS)模型,能够通过输入提示描述模仿特定说话者的风格(性别、音调、说话风格等),生成高质量、听起来自然的语音。...
-
发布了文章 2个月前
Parakeet TDT 0.6B – 英伟达开源的自动语音识别模型
Parakeet TDT 0.6B 是英伟达推出的开源自动语音识别(ASR)模型。采用FastConformer编码器和TDT解码器架构,通过预测文本标记及其持续时间加速推理,减少计算开销。模型在1秒内可转录60分钟音频。...
-
发布了文章 2个月前
ParGo – 字节与中山大学联合推出的多模态大模型连接器
ParGo是字节团队与中山大学合作提出的创新的多模态大语言模型连接器,提升视觉和语言模态在多模态大语言模型(MLLMs)中的对齐效果。通过结合局部token和全局token,使用精心设计的注意力掩码分别提取局部和全局信息。...
-
发布了文章 2个月前
PaperBench – OpenAI 开源的 AI 智能体评测基准
PaperBench是OpenAI开源的AI智能体评测基准,支持评估智能体复现顶级学术论文的能力。PaperBench要求智能体从理解论文内容到编写代码、执行实验,全面展现从理论到实践的自动化能力。PaperBench包含8...
-
发布了文章 2个月前
Paper2Poster – 滑铁卢、新加坡国立和牛津大学推出的学术海报生成框架
Paper2Poster是加拿大滑铁卢大学、新加坡国立大学等机构推出的创新学术框架,基于多模态自动化技术从科学论文生成海报。Paper2Poster推出PosterAgent,一个自顶向下的多智能体系统,支持将长篇论文内容压...
-
发布了文章 2个月前
Paper2Code – AI论文自动转为代码的多智能体框架
Paper2Code 是韩国科学技术院和DeepAuto.ai联合推出的多 Agent 大语言模型(LLM)框架,支持将机器学习领域的科学论文自动转换为可运行的代码仓库。...
-
发布了文章 2个月前
PanoDreamer – 单张图像生成连贯360° 3D场景的新方法
PanoDreamer是能够从单张图像生成连贯的360° 3D场景的新方法。这种方法不同于现有技术,它将问题构建为单图像全景和深度估计的两个优化任务,并引入交替最小化策略来有效解决目标。PanoDreamer能生成全景图像及...
-
发布了文章 2个月前
Pangea – 卡内基梅隆大学开源的多语言多模态大语言模型
Pangea是卡内基梅隆大学团队推出的多语言多模态大型语言模型(LLM),能提升全球语言和文化多样性的覆盖。模型包含600万条指令的多样化数据集,支持39种语言,包含高质量英文指令、机器翻译指令及文化相关任务。Pangea基...
-
发布了文章 2个月前
PaliGemma 2 – 谷歌DeepMind推出的全新视觉语言模型
PaliGemma 2是Google DeepMind基于Gemma 2语言模型家族推出的新一代视觉语言模型(VLM),作为PaliGemma模型的升级版。结合SigLIP-So400m视觉编码器和不同规模的Gemma 2模...
-
发布了文章 2个月前
PaliGemma 2 mix – 谷歌DeepMind推出的升级版视觉语言模型
PaliGemma 2 Mix是谷歌DeepMind发布的最新多任务视觉语言模型(VLM)。集成了多种视觉和语言处理能力,支持图像描述、目标检测、图像分割、OCR以及文档理解等任务,能在单一模型中灵活切换不同功能。...
-
发布了文章 2个月前
PaddleSpeech – 百度飞桨团队开源的语音处理工具
PaddleSpeech 是百度飞桨团队开源的语音处理工具,提供全面的语音处理功能,包括语音识别、语音合成、声纹识别、语音翻译等。PaddleSpeech提供命令行界面、服务器和流式服务器等多种接口,方便快速上手。...