AI工具
发布文章-
发布了文章 2个月前
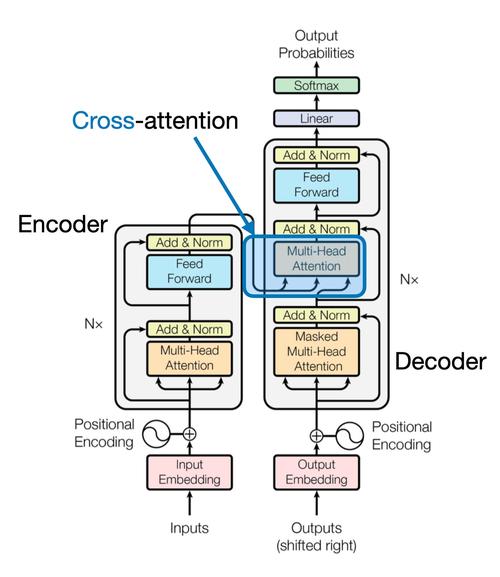
X-baidu09R1 – 基于强化学习的低成本训练框架
X-R1是基于强化学习的低成本训练框架,能加速大规模语言模型的后训练(Scaling Post-Training)开发。X-R1用极低的成本训练0.5B(5亿参数)规模的R1-Zero模型,仅需4块3090或4090 GPU...
-
发布了文章 2个月前
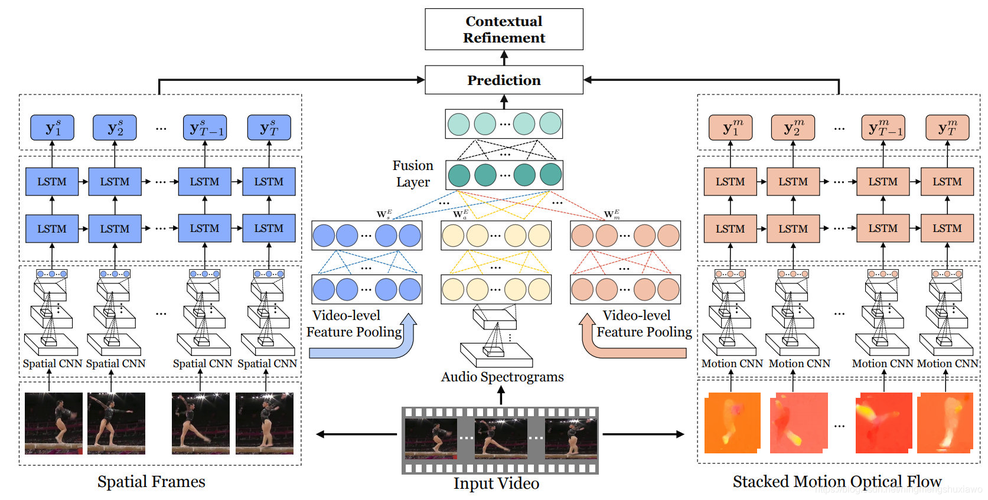
X-baidu09Prompt – 用于多模态视频目标分割的通用框架
X-Prompt是用于多模态视频目标分割的通用框架,解决传统方法在极端光照、快速运动和背景干扰等复杂场景下的局限性。通过预训练一个基于 RGB 数据的视频目标分割基础模型,使用额外的模态信息(如热成像、深度或事件相机数据)作...
-
发布了文章 2个月前
X-baidu09Portrait 2 – 字节跳动推出的单图驱动视频生成模型
X-Portrait 2是字节跳动智能创作团队推出的单图视频驱动技术,基于一张静态照片和一段驱动视频生成高质量、电影级视频。X-Portrait 2保留原图身份特征,准确捕捉细微表情和情绪,实现跨风格动作迁移,适用于写实人像...
-
发布了文章 2个月前
X-baidu09Fusion – 加州大学联合Adobe等机构推出的多模态融合框架
X-Fusion 是加州大学洛杉矶分校、威斯康星大学麦迪逊分校和 Adobe Research 联合提出的多模态融合框架,将预训练的大型语言模型(LLMs)扩展到多模态任务中,保留其语言能力。框架采用双塔架构,冻结语言模型的...
-
发布了文章 2个月前
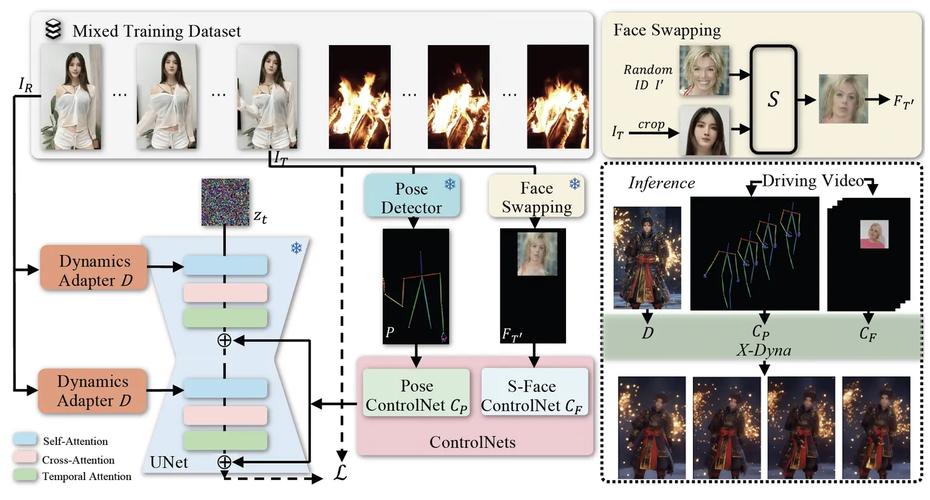
X-baidu09Dyna – 字节联合斯坦福等高校推出的动画生成框架
X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到...
-
发布了文章 2个月前
X-baidu09Dancer – 字节等机构推出音乐驱动的人像舞蹈视频生成框架
X-Dancer 是字节跳动联合加州大学圣地亚哥分校和南加州大学的研究人员共同推出的音乐驱动的人像舞蹈视频生成框架,支持从单张静态图像生成多样化且逼真的全身舞蹈视频。X-Dancer结合自回归变换器(Transformer)...
-
发布了文章 2个月前
X-baidu09AnyLabeling – AI图像标注工具,支持图像和视频多样化标注样式
X-AnyLabeling是集成多种深度学习算法的图像标注软件,专注于提升标注效率和精度。X-AnyLabeling支持图像和视频的多样化标注样式,适配多种AI训练场景,提供图像级与对象级标签分类。软件支持主流深度学习框架的...
-
发布了文章 2个月前
Wuhr AI Ops – AI运维管理平台,提供一站式运维解决方案
Wuhr AI Ops是智能化运维管理平台,通过AI技术简化复杂的运维任务。平台集成多模态AI助手,支持自然语言交互执行运维命令,能一键切换K8s集群和Linux系统命令环境。...
-
发布了文章 2个月前
WriteHERE – 开源的AI长文写作框架,单次生成超长文本
WriteHERE是Jürgen Schmidhuber领衔的团队开源的AI长文写作框架。WriteHERE基于异质递归规划(Heterogeneous Recursive Planning)技术,动态分解写作任务为检索、推...
-
发布了文章 2个月前
WrenAI – 开源的商业AI Agent工具,自然语言生成SQL
WrenAI 是 Canner 推出的开源商业智能 AI Agent工具。通过自然语言交互,帮助用户快速查询、分析和可视化结构化数据,无需编写复杂的 SQL 代码。用户只需用普通语言提出问题,WrenAI 能生成精准的 SQ...
-
发布了文章 2个月前
Wren AI – 开源文本驱动的SQL数据库查询解决方案
Wren AI 是一个开源的文本到 SQL 解决方案,基于自然语言处理技术,支持用户通过自然语言提问执行数据库查询,无需编写复杂的 SQL 代码。支持多种数据库和数据源,包括 PostgreSQL、MySQL、BigQuer...
-
发布了文章 2个月前
WorldVLA – 阿里达摩院联合浙大推出的自回归动作世界模型
WorldVLA是阿里巴巴达摩院和浙江大学联合推出的自回归动作世界模型,模型将视觉-语言-动作(VLA)模型与世界模型整合到一个单一框架中。模型基于动作和图像理解预测未来的图像,目的是学习环境的基本物理规律以改进动作生成。...
-
发布了文章 2个月前
WorldSense – 小红书联合上海交大推出的多模态全面评测新基准
WorldSense是小红书和上海交通大学推出的,用在评估多模态大型语言模型(MLLMs)在现实世界场景中对视觉、听觉和文本输入的综合理解能力的基准测试。WorldSense包含1662个音频-视频同步的多样化视频,覆盖8个...
-
发布了文章 2个月前
WorldScore – 斯坦福大学推出的世界生成模型统一评估基准
WorldScore 是斯坦福大学提出的用于世界生成模型的统一评估基准。将世界生成分解为一系列的下一个场景生成任务,通过明确的基于相机轨迹的布局规范来实现不同方法的统一评估。...
-
发布了文章 2个月前
WorldPM – 阿里Qwen团队联合复旦推出的偏好建模模型系列
WorldPM(World Preference Modeling)是阿里巴巴集团的Qwen团队和复旦大学推出的偏好建模模型系列。基于大规模训练揭示偏好模型的可扩展性。模型基于1500万条偏好数据进行训练,发现偏好模型在客观...